→ بازگشت به شبکههای عصبی پیچشی
معماریهای معروف CNN
VGG-16
VGG-16 شبکهای است که در سال ۲۰۱۴ موفق به کسب ۹۲.۷٪ دقت در طبقهبندی top-5 IoT گردید. ساختار لایهای آن به شکل زیر است:
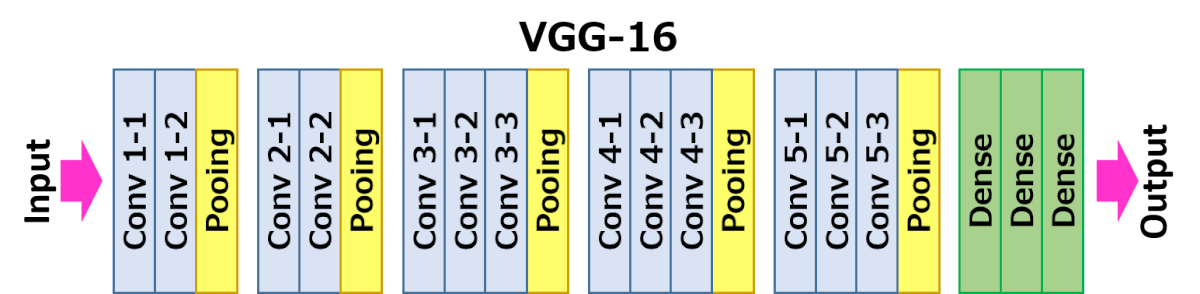
همانطور که مشاهده میشود، VGG از یک معماری هرم سنتی پیروی میکند که شامل لایههای کانولوشن-پولینگ است.
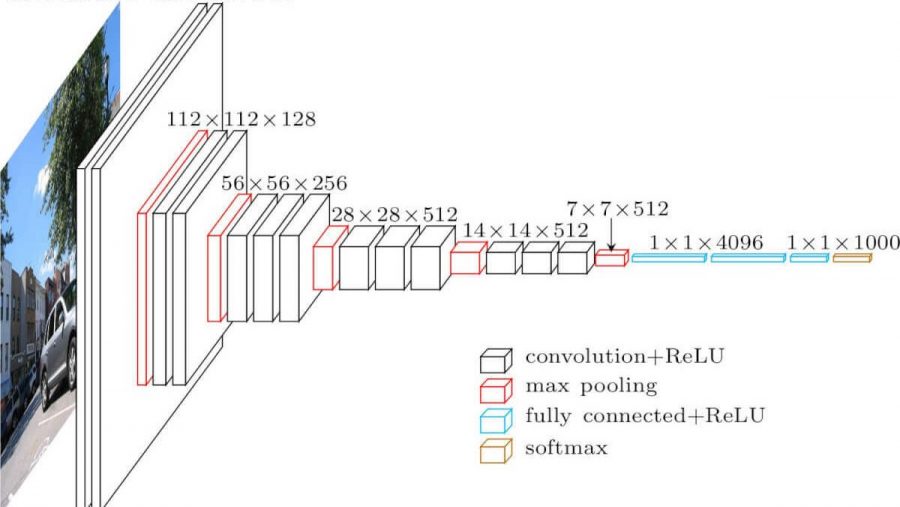
تصویر از Researchgate
ResNet
ResNet خانوادهای از مدلهاست که توسط مایکروسافت در سال ۲۰۱۵ پیشنهاد شد. ایده اصلی ResNet استفاده از بلوکهای باقیمانده است:
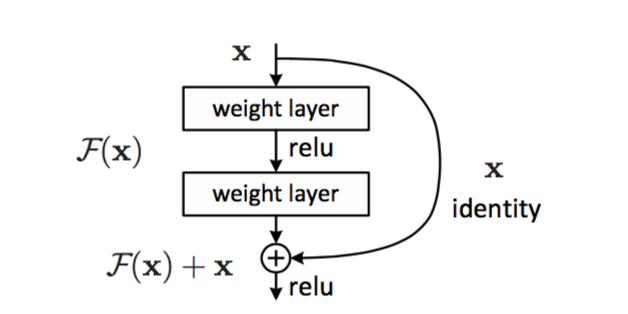
تصویر از این مقاله
علت اضافه شدن یال identity این است که لایه ما تفاوت بین نتیجه یک لایه قبلی و خروجی بلوک باقیمانده را پیشبینی کند؛ لذا نام باقیمانده به آن داده شده است. این بلوکها سهولت بیشتری در فرآیند آموزش دارند و میتوان شبکههایی با چند صد بلوک از این نوع ایجاد کرد (متغیرهای رایج شامل ResNet-52، ResNet-101 و ResNet-152 هستند).
میتوان شبکه را به گونهای تصور کرد که قادر است پیچیدگی خود را با مجموعه دادههای مربوطه منطبق کند. در آغاز فرآیند آموزش شبکه، مقادیر وزنها کوچک هستند و بیشتر سیگنال از لایههای identity عبور میکند. با پیشرفت آموزش و بزرگتر شدن وزنها، اهمیت پارامترهای شبکه افزایش مییابد و شبکه خود را برای تأمین قدرت بیان لازم در راستای طبقهبندی صحیح تصاویر آموزشی تنظیم میکند.
Google Inception
معماری Google Inception این مفهوم را یک قدم جلوتر برده و هر لایه شبکه را به عنوان ترکیبی از چند مسیر مختلف طراحی میکند:
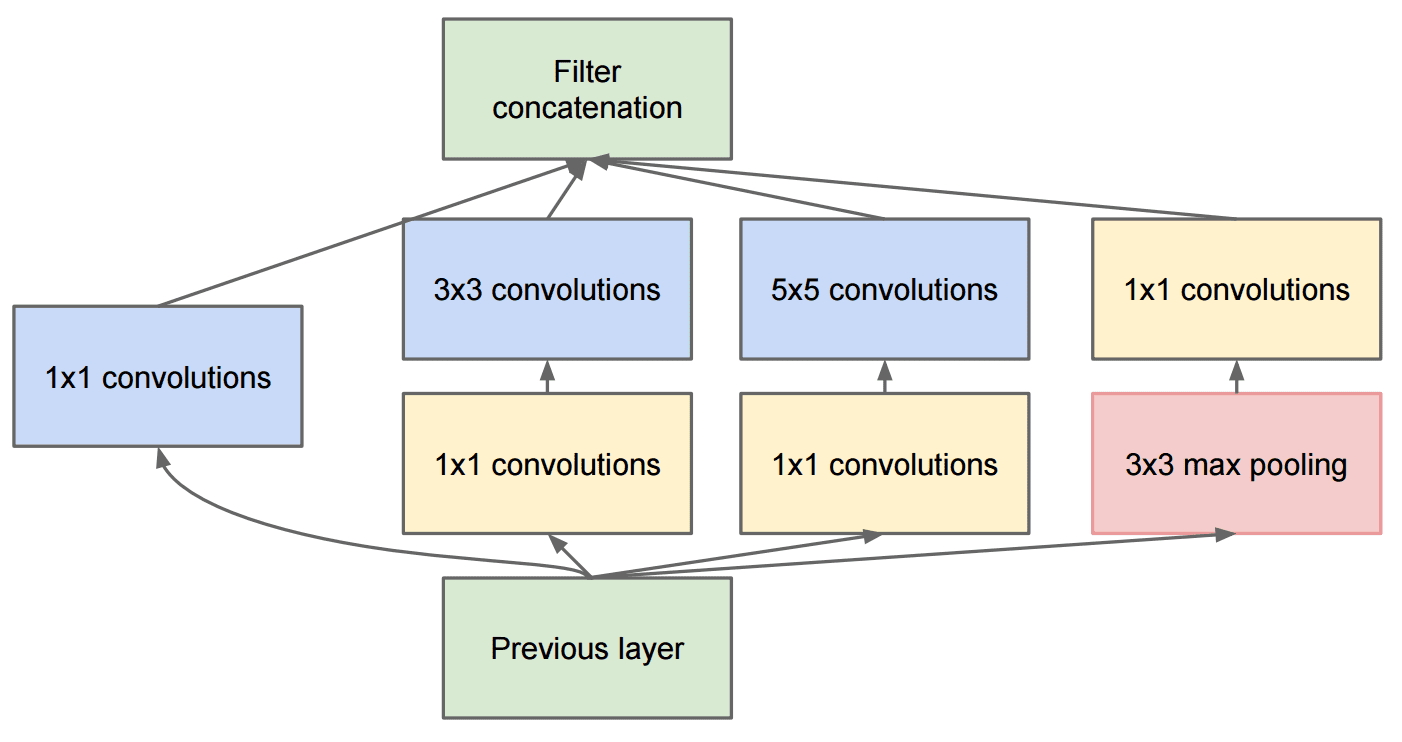
تصویر از Researchgate
در اینجا باید بر نقش کانولوشنهای ۱ در ۱ تأکید کنیم، زیرا در ابتدا این موضوع منطقی به نظر نمیرسد. چرا باید از فیلتر ۱ در ۱ در تصاویر استفاده کرد؟ اما باید به خاطر داشت که فیلترهای کانولوشن همچنین با چندین کانال عمق کار میکنند (در ابتدا - رنگهای RGB، و در لایههای بعدی - کانالهای مربوط به فیلترهای مختلف) و کانولوشن ۱ در ۱ برای ترکیب این کانالهای ورودی با استفاده از وزنهای قابل آموزش مختلف به کار میرود. همچنین میتوان این مفهوم را به عنوان کاهش اندازه (پولینگ) در بعد کانال مشاهده کرد.
اینجا یک پست وبلاگ مفید در این خصوص وجود دارد و همچنین مقاله اصلی قابل ذکر است.
MobileNet
MobileNet خانوادهای از مدلها با ابعاد کاهشیافته است که مناسب دستگاههای همراه هستند. از این مدلها استفاده کنید اگر منابع شما محدود باشد و بخواهید کمی از دقت صرفنظر کنید. ایده اصلی آنها کانولوشنهای جداشدنی عمقمحور است که امکان نمایش فیلترهای کانولوشن را از طریق ترکیب کانولوشنهای فضایی و کانولوشن ۱ در ۱ بر روی کانالهای عمق فراهم میسازد. این روش بهطور قابل توجهی تعداد پارامترها را کاهش میدهد و اندازه شبکه را کوچکتر کرده و همچنین فرآیند آموزش با دادههای محدود را تسهیل میکند.
اینجا یک پست وبلاگ خوب در خصوص MobileNet وجود دارد.
نتیجهگیری
در این واحد، شما با مفهوم اصلی شبکههای عصبی بینایی کامپیوتری - شبکههای کانولوشن آشنا شدید. معماریهای واقعی که به طبقهبندی تصاویر، شناسایی اشیاء و حتی تولید تصاویر قدرت میدهند، همگی بر اساس CNN هستند و فقط با لایههای بیشتر و چند ترفند آموزشی اضافی توسعه یافتهاند.
🚀 چالش
در دفترچههای همراه، یادداشتهایی در انتها درباره چگونگی دستیابی به دقت بیشتر موجود است. چند آزمایش انجام دهید تا ببینید آیا میتوانید دقت بالاتری را به دست آورید.
مرور و مطالعه خودآموزی
در حالی که CNNها بیشتر برای وظایف بینایی کامپیوتری به کار میروند، اما به طور کلی برای استخراج الگوهای با اندازه ثابت مناسب هستند. به عنوان مثال، اگر به پردازش صداها بپردازید، ممکن است بخواهید از CNNها برای جستجوی الگوهای خاص در سیگنال صوتی استفاده کنید - در این حالت فیلترها یک بعدی خواهند بود (و این شبکه CNN به 1D-CNN نامیده میشود). همچنین، گاهی از 3D-CNN برای استخراج ویژگیها در فضای چند بعدی استفاده میشود، مانند رخدادهای خاصی که در ویدیو صورت میگیرند - CNN میتواند برخی الگوهای تغییر ویژگی را در طول زمان ثبت کند. به مطالعه و مرور خودآموزی درباره سایر وظایفی که میتوان با CNNها انجام داد بپردازید.
وظیفه
در این لابراتور، شما مأموریت دارید که نژادهای مختلف گربه و سگ را طبقهبندی کنید. این تصاویر پیچیدهتر از مجموعه داده MNIST هستند و ابعاد بالاتری دارند و شامل بیش از ۱۰ کلاس میباشند.