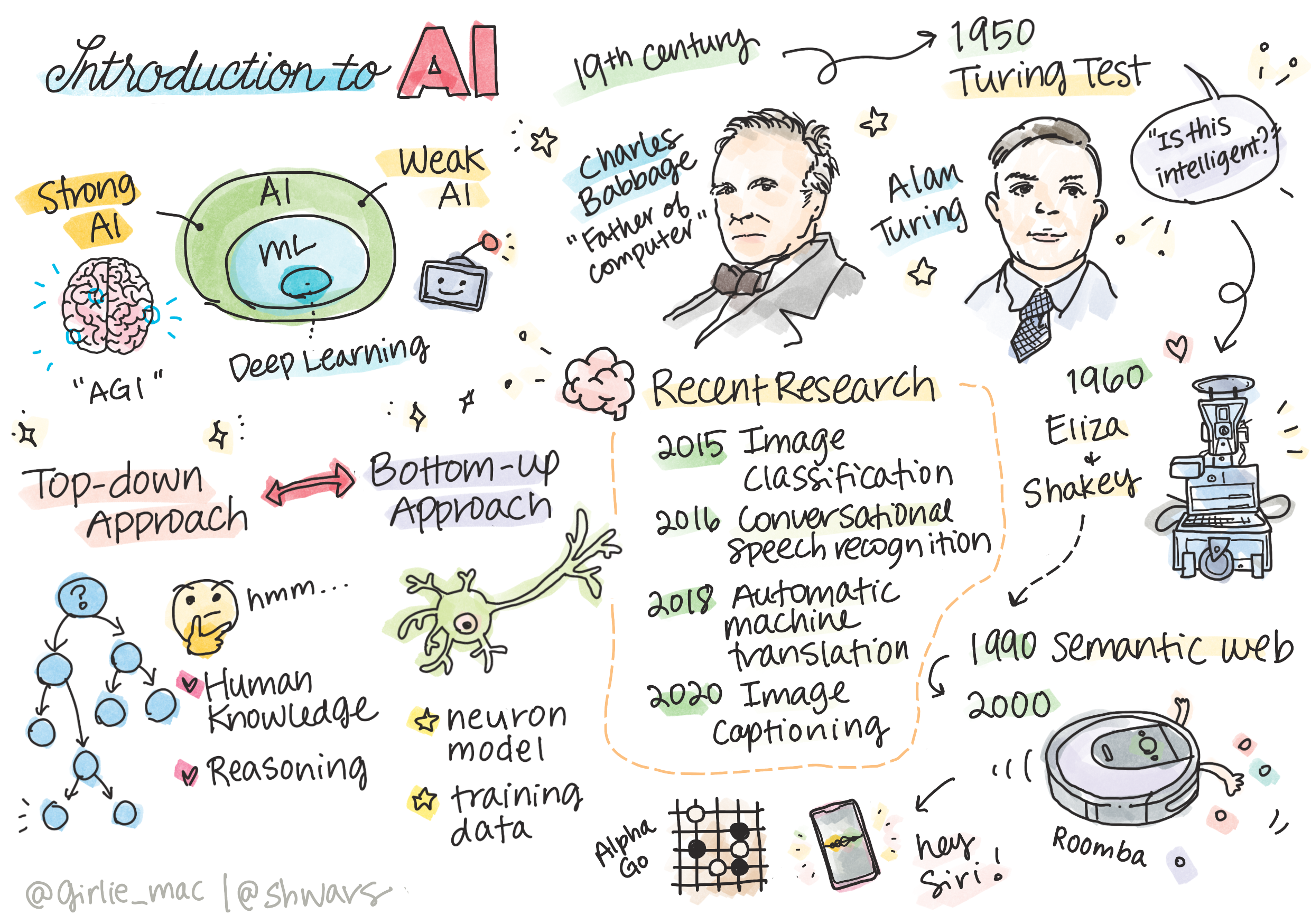
هوش مصنوعی چیست؟
طراحی توسط Tomomi Imura
هوش مصنوعی یک رشتهی علمی جذاب و پویا است که به بررسی و مطالعه دربارهی چگونگی ایجاد رفتار هوشمندانه در رایانهها میپردازد، به عنوان مثال، انجام کارهایی که انسانها در انجام آنها مهارت دارند.
در اصل، رایانهها توسط چارلز بابیج اختراع شدند تا بر روی اعداد با استفاده از یک روش مشخص - یک الگوریتم - کار کنند. رایانههای مدرن، حتی اگر بسیار پیشرفتهتر از مدل اولیه پیشنهاد شده در قرن نوزدهم باشند، همچنان از همان ایده محاسبات کنترلشده پیروی میکنند. بنابراین، اگر ما توالی دقیق مراحل مورد نیاز برای رسیدن به هدف را بدانیم، میتوانیم یک رایانه را برنامهریزی کنیم تا وظیفهای را به انجام برساند.

✅ تعریف سن یک شخص از روی تصویر او، وظیفهای است که نمیتوان به صورت صریح و برنامهریزی شده به رایانه محول کرد، زیرا ما از فرایندی که در ذهنمان برای رسیدن به یک عدد طی میکنیم، آگاهی نداریم.
با این حال، برخی از وظایف وجود دارند که ما به صورت صریح و شفاف از چگونگی حل آنها آگاهی نداریم. برای مثال، تعیین سن یک شخص از روی تصویر او را در نظر بگیرید. ما به نوعی میآموزیم که این کار را انجام دهیم، زیرا نمونههای متعددی از افراد در سنین مختلف را دیدهایم، اما نمیتوانیم به صورت صریح توضیح دهیم که چگونه این کار را انجام میدهیم، و همچنین نمیتوانیم رایانه را برای انجام این کار برنامهریزی کنیم. این دقیقاً همان نوع وظیفهای است که برای هوش مصنوعی (به اختصار AI) جالب و قابل توجه است.
✅ به برخی از وظایفی بیندیشید که میتوانید به یک رایانه واگذار کنید و از هوش مصنوعی بهرهمند شوید. زمینههای مالی، پزشکی و هنر را در نظر بگیرید - این زمینهها امروزه چگونه از هوش مصنوعی سود میبرند؟
هوش مصنوعی ضعیف در برابر هوش مصنوعی قوی
هوش مصنوعی ضعیف به سیستمهایی از هوش مصنوعی اطلاق میشود که برای انجام یک وظیفه مشخص یا مجموعهای محدود از وظایف طراحی و آموزش دیدهاند.
این سیستمها به طور کلی از هوشمندی عمومی برخوردار نیستند؛ آنها در اجرای وظایف از پیش تعیینشده تبحر دارند، اما فاقد درک واقعی یا آگاهی هستند.
نمونههایی از هوش مصنوعی ضعیف شامل دستیاران مجازی مانند سیری یا الکسا، الگوریتمهای پیشنهادی مورد استفاده در سرویسهای پخش جریانی و چتباتهایی هستند که برای انجام وظایف خاص در خدمات مشتری طراحی شدهاند.
هوش مصنوعی ضعیف بسیار تخصصی است و تواناییهای شناختی شبیه به انسان یا قابلیتهای حل مسئله عمومی فراتر از دامنه محدود خود را ندارد.
هوش مصنوعی قوی، یا هوش مصنوعی عمومی (AGI)، به سیستمهایی از هوش مصنوعی اطلاق میشود که از هوش و درک در سطح انسان برخوردار هستند.
این سیستمهای هوش مصنوعی قادر به انجام هر وظیفهی فکریای هستند که یک انسان میتواند انجام دهد، به حوزههای مختلف سازگار شوند و نوعی آگاهی یا خودآگاهی داشته باشند.
دستیابی به هوش مصنوعی قوی، یک هدف بلندمدت در پژوهشهای هوش مصنوعی است و نیازمند توسعهی سیستمهای هوش مصنوعیای است که بتوانند در طیف وسیعی از وظایف و زمینهها، استدلال، یادگیری، درک و سازگاری کنند.
هوش مصنوعی قوی در حال حاضر یک مفهوم نظری است و تاکنون هیچ سیستم هوش مصنوعی به این سطح از هوش عمومی نرسیده است.
تعریف هوش و آزمون تورینگ
یکی از چالشهای اساسی در مواجهه با مفهوم هوش، فقدان یک تعریف روشن و دقیق از این اصطلاح است. میتوان استدلال نمود که هوش با توانایی تفکر انتزاعی یا خودآگاهی مرتبط است، اما ارائه یک تعریف جامع و مانعی که مورد توافق همگان باشد، دشوار است.

برای درک بهتر ابهام در تعریف هوش، میتوانید به این پرسش پاسخ دهید: "آیا یک گربه باهوش است؟" افراد مختلف ممکن است پاسخهای متفاوتی به این پرسش دهند، زیرا هیچ آزمون جهانی پذیرفتهشدهای برای اثبات یا رد این ادعا وجود ندارد. و اگر فکر میکنید چنین آزمونی وجود دارد، پیشنهاد میشود گربه خود را در یک آزمون هوش (IQ) شرکت دهید...
✅ لحظهای تأمل کنید که شما چگونه هوش را تعریف میکنید. آیا یک کلاغ که قادر به حل ماز و دستیابی به غذاست، باهوش محسوب میشود؟ آیا یک کودک باهوش است؟
هنگامی که در مورد هوش مصنوعی عمومی (AGI) سخن به میان میآید، لازم است روشی برای تشخیص این موضوع داشته باشیم که آیا یک سیستم حقیقتاً هوشمند ایجاد کردهایم یا خیر. آلن تورینگ، آزمون تورینگ را به عنوان یک تعریف از هوش پیشنهاد نمود. این آزمون، یک سیستم مشخص را با چیزی که ذاتاً هوشمند است - یک انسان واقعی - مقایسه میکند و به دلیل اینکه هر مقایسهی خودکار میتواند توسط یک برنامه کامپیوتری دور زده شود، از یک بازجو انسانی استفاده میشود. بنابراین، اگر یک انسان نتواند بین یک شخص واقعی و یک سیستم کامپیوتری در یک گفتگوی متنی تمایز قائل شود، آن سیستم هوشمند در نظر گرفته میشود.
یک چتبات به نام یوجین گوستمن، که در سنت پترزبورگ توسعه یافته بود، در سال 2014 با استفاده از یک ترفند شخصیتی هوشمندانه به نزدیکی گذراندن آزمون تورینگ رسید. این چتبات از ابتدا اعلام کرد که یک پسر 13 ساله اوکراینی است، که این امر میتوانست فقدان دانش و برخی تناقضات در متن را توجیه کند. این بات پس از 5 دقیقه گفتگو، 30٪ از داوران را متقاعد کرد که انسان است، معیاری که تورینگ معتقد بود یک ماشین تا سال 2000 قادر به گذراندن آن خواهد بود. با این حال، باید درک کرد که این به معنای ایجاد یک سیستم هوشمند یا فریب دادن بازجوی انسانی توسط یک سیستم کامپیوتری نیست - این سیستم نبود که انسانها را فریب داد، بلکه سازندگان بات بودند!
✅ آیا تا به حال توسط یک چتبات به اشتباه افتادهاید و گمان کردهاید که با یک انسان صحبت میکنید؟ چگونه شما را متقاعد کرد؟
رویکردهای گوناگون در حوزه هوش مصنوعی
چنانچه بخواهیم یک رایانه همانند یک انسان رفتار نماید، لازم است به نوعی شیوه تفکر انسانی را در درون یک رایانه شبیهسازی کنیم. بدین ترتیب، ضروری است تلاش نماییم تا دریابیم چه عواملی یک انسان را هوشمند میسازد.
برای آنکه قادر باشیم هوش را در یک ماشین برنامهریزی کنیم، باید درک کنیم که فرآیندهای تصمیمگیری ما چگونه عمل میکنند. اگر اندکی به درون خود بنگریم، درخواهیم یافت که برخی فرآیندها به صورت ناخودآگاه رخ میدهند - برای مثال، ما میتوانیم یک گربه را از یک سگ بدون تفکر آگاهانه تشخیص دهیم - در حالی که برخی دیگر مستلزم استدلال هستند.
دو رویکرد محتمل برای حل این مسئله وجود دارد:
| رویکرد از پایین به بالا (شبکههای عصبی) | رویکرد از بالا به پایین (استدلال نمادین) |
|---|---|
| رویکرد از پایین به بالا، ساختار مغز انسان را مدل میکند که از تعداد بسیار زیادی واحدهای ساده به نام نورون تشکیل شده است. هر نورون مانند یک میانگین وزنی از ورودیهایش عمل میکند و ما میتوانیم یک شبکه از نورونها را برای حل مسائل مفید با ارائه دادههای آموزشی، آموزش دهیم. | رویکرد از بالا به پایین، شیوهای را مدل میکند که یک شخص برای حل یک مسئله استدلال میکند. این رویکرد شامل استخراج دانش از یک انسان و نمایش آن به شکلی قابل خواندن برای کامپیوتر است. همچنین نیاز به توسعه راهی برای مدلسازی استدلال در داخل یک کامپیوتر داریم. |
علاوه بر این، برخی دیگر از رویکردهای مرتبط با هوش وجود دارند:
-
رویکردهای ظهوریافته، سینرژیک یا چندعاملی بر این اصل استوارند که رفتار هوشمند پیچیده میتواند از تعامل و همکاری تعداد کثیری از عوامل ساده حاصل گردد. بر اساس سایبرنتیک تکاملی، هوش میتواند از رفتارهای سادهتر و واکنشی در فرآیند گذار متاسیستمی پدیدار شود.
-
رویکرد تکاملی، یا الگوریتم ژنتیک، یک فرآیند بهینهسازی است که بر پایه اصول تکامل بنا شده است.
ما در ادامه این دوره به بررسی این رویکردها خواهیم پرداخت، اما در حال حاضر تمرکز اصلی ما بر دو جهتگیری اصلی خواهد بود: رویکرد از بالا به پایین و رویکرد از پایین به بالا.
رویکرد از بالا به پایین
در یک رویکرد از بالا به پایین، ما تلاش میکنیم تا استدلال خود را مدلسازی نماییم. از آنجایی که قادر به پیگیری افکار خود در هنگام استدلال هستیم، میتوانیم بکوشیم تا این فرآیند را به صورت رسمی درآورده و آن را در رایانه برنامهریزی کنیم. این روش، استدلال نمادین نامیده میشود.
افراد تمایل به داشتن قوانینی در ذهن خود دارند که فرآیند تصمیمگیری آنها را هدایت میکند. برای مثال، زمانی که یک پزشک در حال تشخیص بیماری یک بیمار است، ممکن است متوجه شود که فرد تب دارد و بنابراین احتمال وجود التهاب در بدن وجود دارد. با اعمال مجموعهای گسترده از قوانین به یک مشکل خاص، یک پزشک ممکن است قادر به ارائه تشخیص نهایی باشد.
این رویکرد به شدت به نمایش دانش و استدلال وابسته است. استخراج دانش از یک متخصص انسانی ممکن است دشوارترین بخش باشد، زیرا یک پزشک در بسیاری از موارد دقیقاً نمیداند که چرا به یک تشخیص خاص میرسد. گاهی اوقات راه حل بدون تفکر صریح در ذهن او ظاهر میشود. برخی از وظایف، مانند تعیین سن یک فرد از روی عکس، به هیچ وجه قابل تقلیل به دستکاری دانش نیست.
رویکرد از پایین به بالا
در مقابل، ما میتوانیم تلاش کنیم تا سادهترین عناصر داخل مغز خود - یک نورون - را مدل کنیم. ما قادر به ساخت یک شبکه عصبی مصنوعی در داخل یک رایانه هستیم و سپس میتوانیم با ارائه مثالهایی به آن، حل مشکلات را به آن آموزش دهیم. این فرآیند مشابه نحوه یادگیری یک نوزاد از محیط اطراف خود با انجام مشاهدات است.
✅ پیشنهاد میشود در مورد نحوه یادگیری نوزادان تحقیق بیشتری انجام شود. عناصر اساسی مغز یک نوزاد چیست؟
تاریخچهی مختصری از هوش مصنوعی
حوزهی هوش مصنوعی در میانهی قرن بیستم پایهگذاری شد. در آغاز، استدلال نمادین به عنوان یک رویکرد مرسوم مورد استفاده قرار میگرفت و به تعدادی موفقیتهای چشمگیر، همچون سیستمهای خبره - برنامههای رایانهای که قادر به ایفای نقش به عنوان یک متخصص در برخی از حوزههای مسئلهی محدود بودند - منجر شد. با این حال، به سرعت آشکار گردید که این رویکرد از مقیاسپذیری مناسبی برخوردار نیست. استخراج دانش از یک متخصص، بازنمایی آن در یک رایانه و حفظ صحت و دقت این پایگاه دانش، وظیفهای بسیار پیچیده و در بسیاری از موارد بسیار پرهزینه برای عملی بودن است. این موضوع به آنچه که به عنوان "زمستان هوش مصنوعی" در دههی 1970 شناخته میشود، انجامید.
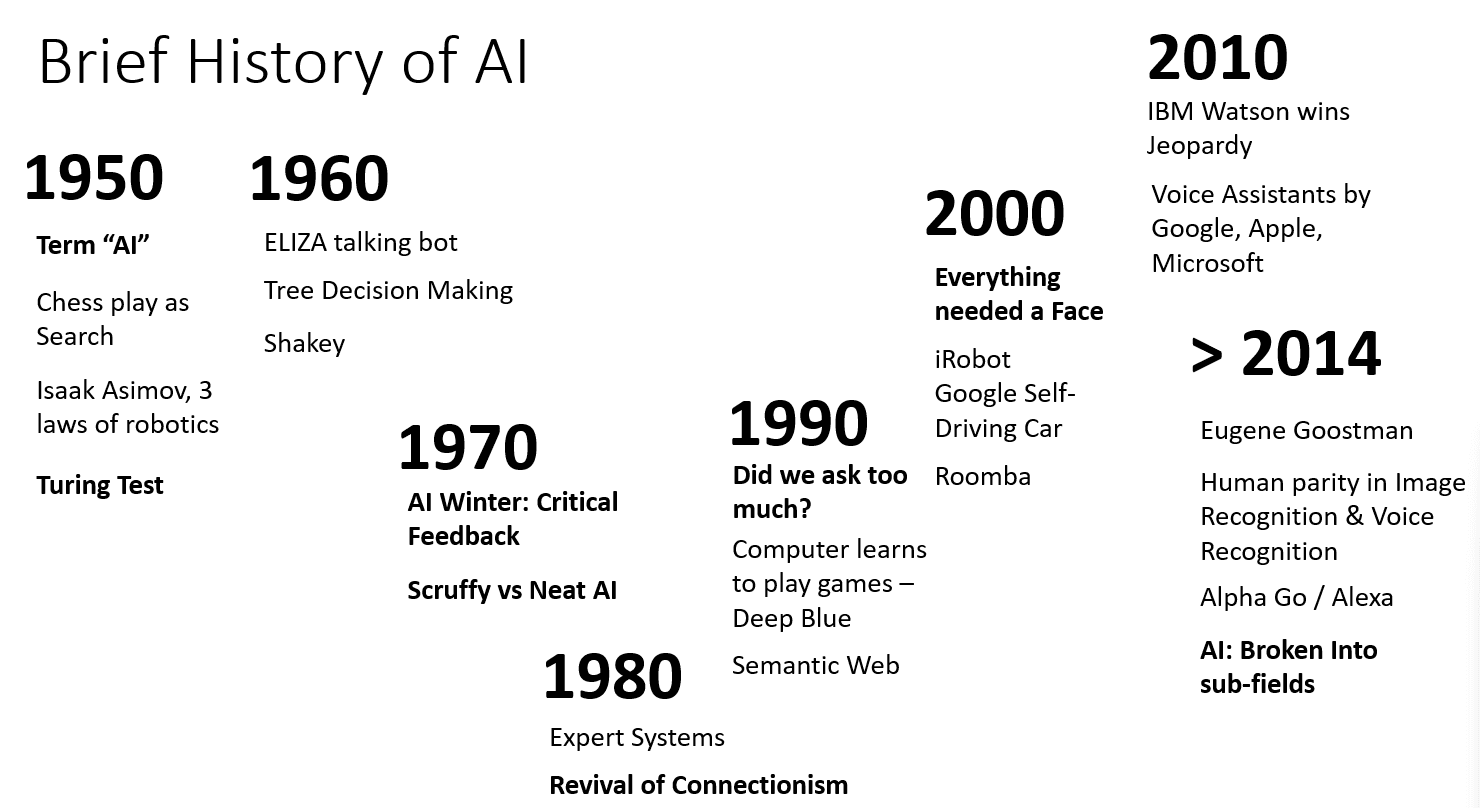
با گذشت زمان، منابع محاسباتی مقرونبهصرفهتر شدند و دادههای بیشتری در دسترس قرار گرفتند. در نتیجه، رویکردهای مبتنی بر شبکههای عصبی شروع به نشان دادن عملکردی عالی در رقابت با انسانها در بسیاری از زمینهها، مانند بینایی کامپیوتری یا درک گفتار نمودند. در دهه گذشته، اصطلاح هوش مصنوعی بیشتر به عنوان مترادفی برای شبکههای عصبی استفاده شده است، زیرا بیشتر موفقیتهای هوش مصنوعی که در مورد آنها میشنویم بر پایه شبکههای عصبی استوار هستند.
ما میتوانیم مشاهده کنیم که چگونه رویکردها در طول زمان تغییر کردهاند، برای مثال، در ایجاد یک برنامه کامپیوتری بازی شطرنج:
برنامههای اولیه شطرنج بر پایه جستجو بودند - یک برنامه به صراحت سعی میکرد حرکات احتمالی یک حریف را برای تعداد مشخصی از حرکات بعدی تخمین بزند و بر اساس موقعیت بهینه که میتوان در چند حرکت به دست آورد، یک حرکت بهینه را انتخاب کند. این رویکرد منجر به توسعه الگوریتم جستجوی هرس آلفا-بتا شد.
استراتژیهای جستجو در پایان بازی به خوبی کار میکنند، جایی که فضای جستجو با تعداد کمی از حرکات ممکن محدود میشود. با این حال، در ابتدای بازی، فضای جستجو بسیار بزرگ است و الگوریتم را میتوان با یادگیری از مسابقات موجود بین بازیکنان انسانی بهبود بخشید. آزمایشهای بعدی از استدلال مبتنی بر مورد استفاده کردند، جایی که برنامه به دنبال موارد بسیار مشابه با موقعیت فعلی در بازی در پایگاه دانش بود.
برنامههای مدرن که بر بازیکنان انسانی پیروز میشوند، بر پایه شبکههای عصبی و یادگیری تقویتی هستند، جایی که برنامهها یاد میگیرند که تنها با بازی طولانی مدت در برابر خود و یادگیری از اشتباهات خود بازی کنند - بسیار شبیه به کاری که انسانها هنگام یادگیری بازی شطرنج انجام میدهند. با این حال، یک برنامه کامپیوتری میتواند بازیهای بسیار بیشتری را در زمان بسیار کمتری انجام دهد و بنابراین میتواند بسیار سریعتر یاد بگیرد.
✅ کمی تحقیق در مورد سایر بازیهایی که توسط هوش مصنوعی انجام شده است، انجام دهید.
به طور مشابه، ما میتوانیم ببینیم که چگونه رویکرد نسبت به ایجاد "برنامههای گفتاری" (که ممکن است تست تورینگ را پشت سر بگذارند) تغییر کرده است:
برنامههای اولیه از این نوع مانند الیزا، بر پایه قوانین دستوری بسیار ساده و فرمولبندی مجدد جمله ورودی به یک سوال بودند.
دستیارهای مدرن، مانند کورتانا، سیری یا دستیار گوگل، همگی سیستمهای هیبریدی هستند که از شبکههای عصبی برای تبدیل گفتار به متن و تشخیص هدف ما استفاده میکنند و سپس برخی از استدلالها یا الگوریتمهای صریح را برای انجام اقدامات مورد نیاز به کار میگیرند.
در آینده، ممکن است انتظار یک مدل کاملاً مبتنی بر شبکه عصبی را برای مدیریت گفتگو به تنهایی داشته باشیم. خانواده اخیر شبکههای عصبی GPT و Turing-NLG موفقیت بزرگی در این زمینه نشان میدهند.

تحقیقات نوین هوش مصنوعی
رشد فزایندهی اخیر در مطالعات مربوط به شبکههای عصبی، از حوالی سال ۲۰۱۰ میلادی آغاز گردید، مقطعی که در آن، پایگاههای دادهی عمومی وسیعی در دسترس قرار گرفتند. یکی از این مجموعهها، ImageNet نام دارد که مشتمل بر حدود ۱۴ میلیون تصویر همراه با توضیحات مربوطه است و زمینهساز پیدایش چالش تشخیص بصری در مقیاس بزرگ ImageNet گردید.
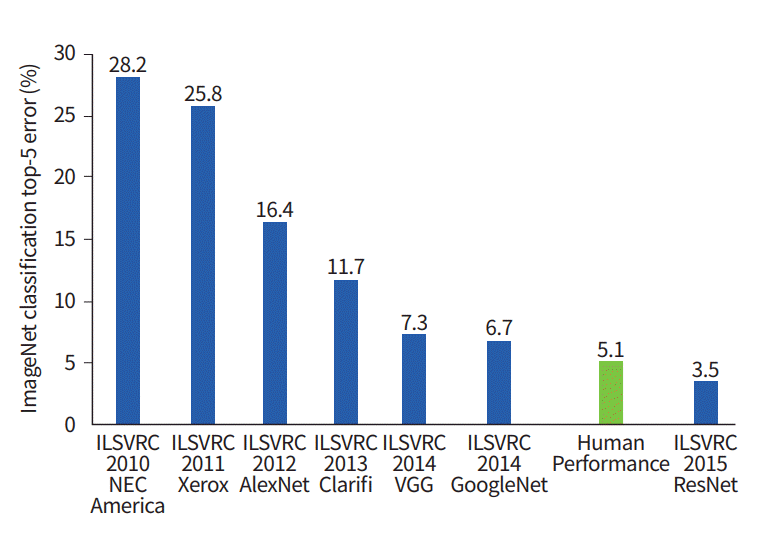
در سال ۲۰۱۲ میلادی، برای نخستین بار شبکههای عصبی پیچشی (Convolutional Neural Networks) در حوزه طبقهبندی تصاویر به کار گرفته شدند که نتیجه آن، کاهش چشمگیر خطاهای طبقهبندی (از حدود ۳۰ درصد به ۱۶.۴ درصد) بود. در سال ۲۰۱۵، معماری ResNet که توسط مایکروسافت ریسرچ ارائه گردید، به سطح دقت انسانی در این زمینه دست یافت.
از آن زمان به بعد، شبکههای عصبی در انجام بسیاری از وظایف، موفقیت قابل توجهی از خود به نمایش گذاشتهاند:
| سال | دستیابی به برابری با انسان |
|---|---|
| ۲۰۱۵ | طبقهبندی تصویر |
| ۲۰۱۶ | شناسایی گفتار محاورهای |
| ۲۰۱۸ | ترجمه ماشینی خودکار (چینی به انگلیسی) |
| ۲۰۲۰ | توضیح تصویر |
در چند سال گذشته، ما شاهد موفقیتهای عظیمی با مدلهای زبانی بزرگ، مانند BERT و GPT-3 بودهایم. این امر عمدتاً به این دلیل اتفاق افتاده است که دادههای متنی عمومی زیادی در دسترس است که به ما امکان میدهد مدلهایی را برای درک ساختار و معنای متون آموزش دهیم، آنها را بر روی مجموعههای متنی عمومی پیشآموزش دهیم و سپس این مدلها را برای وظایف خاصتر تخصص دهیم. در ادامه این دوره بیشتر در مورد پردازش زبان طبیعی خواهیم آموخت.