بازنمایی دانش و سامانههای متخصص
طراحی توسط Tomomi Imura
تلاش برای دستیابی به هوش مصنوعی، مبتنی بر جستجوی دانش با هدف درک جهان به شیوهای مشابه با انسانهاست. اما برای نیل به این مقصود، چه راهی باید پیمود؟
در آغازین روزهای هوش مصنوعی، رویکرد از بالا به پایین برای ایجاد سامانههای هوشمند (که در درس پیشین به بحث گذاشته شد) رواج داشت. اندیشه اصلی این بود که دانش را از افراد به گونهای قابل خواندن برای ماشین استخراج کنند و سپس از آن برای حل خودكار مسائل بهره گیرند. این رویکرد بر پایه دو ایده بزرگ استوار بود:
- بازنمایی دانش
- استدلال
بازنمایی دانش و استدلال (Knowledge representation and reasoning)
یکی از مفاهیم بنیادین در هوش مصنوعی نمادین، دانش میباشد. تمایز میان دانش، اطلاعات و دادهها از اهمیت ویژهای برخوردار است. برای نمونه، میتوان بیان داشت که کتابها حاوی دانش هستند، چرا که مطالعه کتابها میتواند فرد را به یک متخصص تبدیل نماید. با این حال، آنچه که کتابها در حقیقت در بر دارند، داده نامیده میشود و با مطالعه کتابها و ادغام این دادهها در مدل ذهنی جهان خود، این دادهها به دانش تبدیل میگردند.
✅ دانش، مفهومی است که در ذهن ما جای دارد و درک ما از جهان را نمایندگی میکند. این دانش از طریق یک فرآیند یادگیری فعال به دست میآید که در آن، قطعات اطلاعاتی دریافتی در مدل فعال جهان ما ادغام میشوند.
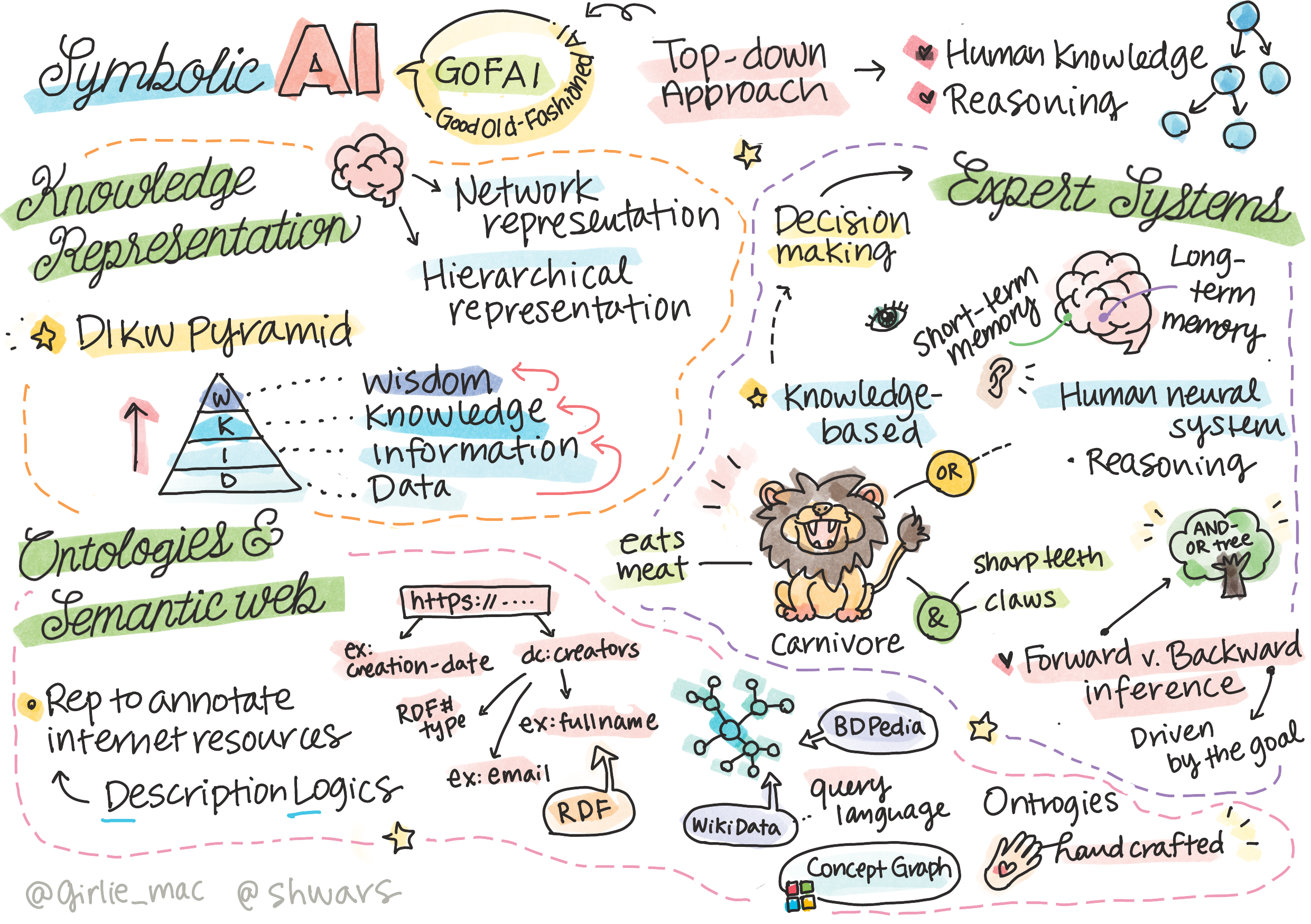
غالباً، ما دانش را به طور دقیق تعریف نمیکنیم، اما آن را با سایر مفاهیم مرتبط، با استفاده از هرم DIKW هماهنگ میسازیم. این هرم شامل مفاهیم زیر است:
داده، مفهومی است که در رسانههای فیزیکی مانند متن نوشته شده یا کلمات گفته شده، نمود مییابد. دادهها به صورت مستقل از انسان وجود دارند و قابلیت انتقال میان افراد را دارا هستند.
اطلاعات، نحوه تفسیر دادهها در ذهن ماست. برای مثال، هنگامی که کلمه "کامپیوتر" را میشنویم، درکی از آن در ذهن ما شکل میگیرد.
دانش، اطلاعاتی است که در مدل جهان ما ادغام شده است. برای مثال، هنگامی که میآموزیم کامپیوتر چیست، شروع به شکلدهی ایدههایی در مورد نحوه کار آن، هزینه آن و کاربردهای آن میکنیم. این شبکه از مفاهیم مرتبط، دانش ما را تشکیل میدهد.
حکمت، سطح بالاتری از درک ما از جهان است و به معرفتشناسی، یعنی درک نحوه و زمان استفاده از دانش، اشاره دارد.
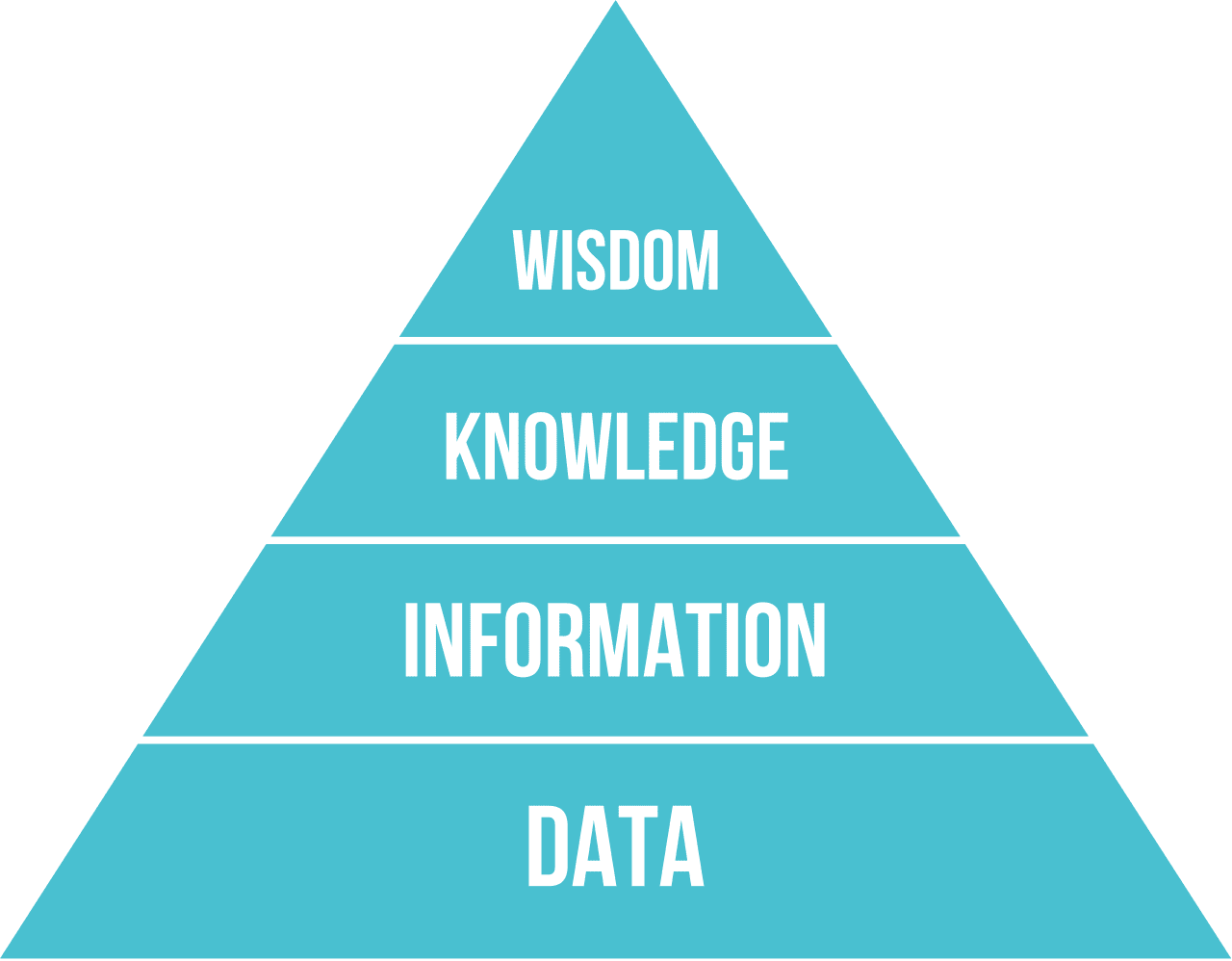 Image from Wikipedia, By Longlivetheux - Own work, CC BY-SA 4.0
Image from Wikipedia, By Longlivetheux - Own work, CC BY-SA 4.0
بنابراین، مسئلهی بازنمایی دانش عبارت است از یافتن شیوهای کارآمد برای تجسم و نمایش دانش در درون یک رایانه به شکل داده، به نحوی که بتوان به طور خودکار از آن بهره برد. این موضوع را میتوان به عنوان یک طیف در نظر گرفت:
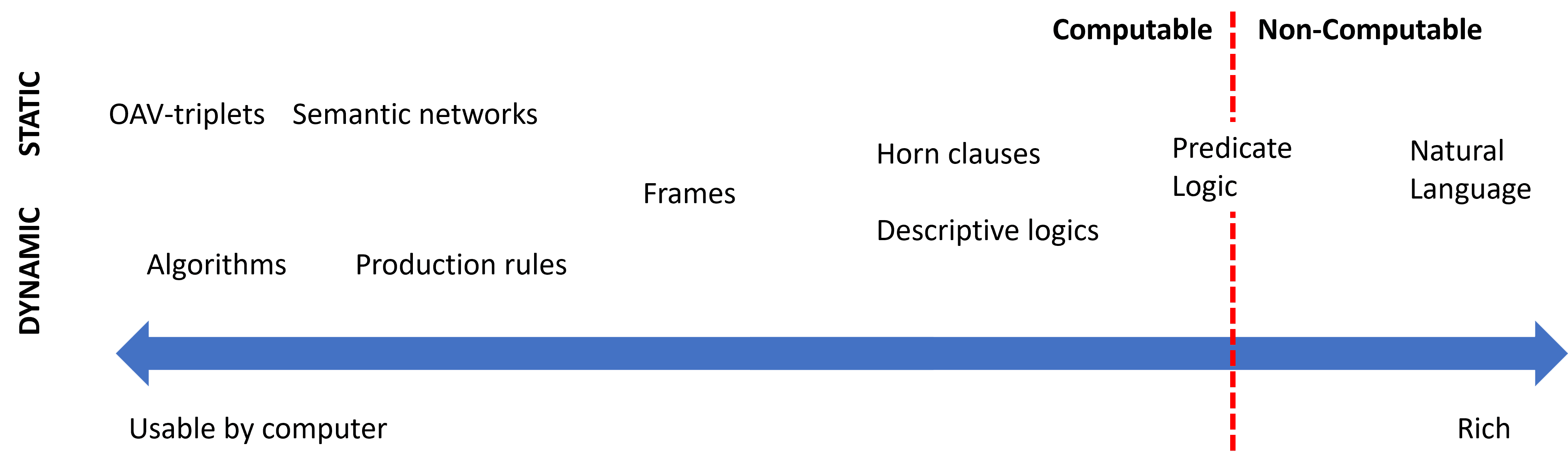 Image by Dmitry Soshnikov
Image by Dmitry Soshnikov
در سمت چپ، اشکال بسیار سادهای از بازنماییهای دانش وجود دارند که رایانهها میتوانند به طور موثر از آنها استفاده کنند. سادهترین نوع، الگوریتمی است، به این معنا که دانش به وسیلهی یک برنامه رایانهای بازنمایی میشود. با این حال، این روش بهترین راه برای بازنمایی دانش نیست، زیرا از انعطافپذیری لازم برخوردار نیست. دانش درون ذهن ما اغلب غیر الگوریتمی است.
در سمت راست، بازنماییهایی مانند متن طبیعی قرار دارند. این نوع، قدرتمندترین شکل بازنمایی دانش است، اما نمیتوان از آن برای استدلال خودکار بهره برد.
✅ لحظهای تأمل کنید که چگونه دانش را در ذهن خود بازنمایی میکنید و آن را به یادداشت تبدیل مینمایید. آیا قالب خاصی وجود دارد که برای کمک به حفظ کردن اطلاعات، برای شما موثر باشد؟
طبقهبندی روشهای بازنمایی دانش کامپیوتری
ما قادر به طبقهبندی روشهای گوناگون بازنمایی دانش کامپیوتری در دستههای زیر هستیم:
- بازنماییهای شبکهای بر این پایه استوارند که در ذهن ما شبکهای از مفاهیم مرتبط با یکدیگر وجود دارد. ما میتوانیم کوشش کنیم تا همان شبکهها را به عنوان یک گراف در درون یک رایانه بازسازی کنیم - که به آن شبکه معنایی گفته میشود.
- سه تاییهای شیء-صفت-مقدار یا جفتهای صفت-مقدار. از آنجایی که یک گراف میتواند در درون یک رایانه به عنوان یک فهرست از گرهها و یالها بازنمایی شود، ما میتوانیم یک شبکه معنایی را به وسیله یک فهرست از سه تاییها، شامل اشیا، صفات و مقادیر، بازنمایی کنیم. برای نمونه، ما سه تاییهای زیر را درباره زبانهای برنامهنویسی ایجاد میکنیم:
| شیء | صفت | مقدار |
|---|---|---|
| پایتون | هست | زبان بدون نوع (type) |
| پایتون | ساخته شده توسط | Guido van Rossum |
| پایتون | block-syntax | indentation |
| زبان بدون نوع | ندارد | تعریف نوع متغیر ها |
✅ به این فکر کنید که چگونه میتوان از سه تاییها برای بازنمایی سایر انواع دانش استفاده کرد.
-
بازنماییهای سلسله مراتبی بر این واقعیت تأکید دارند که ما اغلب در ذهن خود یک سلسله مراتب از اشیا خلق میکنیم. برای نمونه، ما آگاهیم که قناری یک پرنده است و همه پرندگان بال دارند. ما همچنین درکی از رنگ معمول قناری و سرعت پرواز آنها داریم.
- بازنمایی قاب (Frame representation) بر پایه بازنمایی هر شیء یا دسته از اشیا به عنوان یک قاب است که شامل شکافها میباشد. شکافها دارای مقادیر پیشفرض احتمالی، محدودیتهای ارزش یا رویههای ذخیرهشدهای هستند که میتوان برای به دست آوردن ارزش یک شکاف آنها را فراخوانی نمود. همه قابها یک سلسله مراتب مشابه با سلسله مراتب اشیا در زبانهای برنامهنویسی شیءگرا تشکیل میدهند.
- سناریوها نوعی ویژه از قابها هستند که موقعیتهای پیچیدهای را که میتوانند در طول زمان آشکار گردند، نمایندگی میکنند.
پایتون
| شکاف | مقدار | مقدار اولیه | بازه |
|---|---|---|---|
| نام | پایتون | ||
| هست | یک زبان بدون نوع | ||
| نحوه نام گذاری متغیر ها | CamelCase | ||
| طول برنامه | ۵-۵۰۰۰ خط | ||
| Block Syntax | Indent |
-
بازنماییهای رویه ای (Procedural representations) بر پایه بازنمایی دانش به وسیله فهرستی از اقدامات هستند که در صورت وقوع یک شرط خاص قابل اجرا میباشند.
- قوانین تولید، عبارتهایی از نوع if-then هستند که به ما امکان میدهند نتیجهگیری کنیم. برای نمونه، یک پزشک میتواند قانونی داشته باشد که میگوید اگر بیمار تب بالا یا سطح بالایی از پروتئین واکنشی C در آزمایش خون داشته باشد آنگاه او دچار التهاب است. هنگامی که با یکی از شرایط مواجه میشویم، میتوانیم در مورد التهاب نتیجهگیری کنیم و سپس از آن در استدلال بیشتر بهره ببریم.
- الگوریتمها را میتوان به عنوان شکلی دیگر از بازنمایی رویه ای در نظر گرفت، اگرچه تقریباً هرگز مستقیماً در سیستمهای مبتنی بر دانش به کار گرفته نمیشوند.
-
منطق (Logic) در ابتدا توسط ارسطو به عنوان شیوهای برای بازنمایی دانش جهانی انسان پیشنهاد شد.
- منطق گزاره (Predicate Logic) به عنوان یک نظریه ریاضی بسیار غنی است و قابل محاسبه نیست، بنابراین معمولاً از زیرمجموعهای از آن استفاده میشود، مانند بندهای Horn که در Prolog به کار گرفته میشود.
- منطق توصیفی خانوادهای از نظامهای منطقی است که برای بازنمایی و استدلال در مورد سلسله مراتب اشیا و بازنماییهای توزیعشده دانش مانند وب معنایی به کار میرود.
سامانههای متخصص
یکی از موفقیتهای اولیه در حوزه هوش مصنوعی نمادین، سیستمهایی تحت عنوان سامانههای متخصص بودند. این سیستمهای کامپیوتری به گونهای طراحی شده بودند که در حوزههای محدودی، به عنوان یک متخصص عمل نمایند. بنیان این سیستمها بر اساس یک پایگاه دانش بود که از یک یا چند متخصص انسانی استخراج شده بود. همچنین، این سیستمها مجهز به یک موتور استنتاج بودند که فرآیند استدلال و نتیجهگیری را بر پایه دانش مذکور انجام میداد.
 | 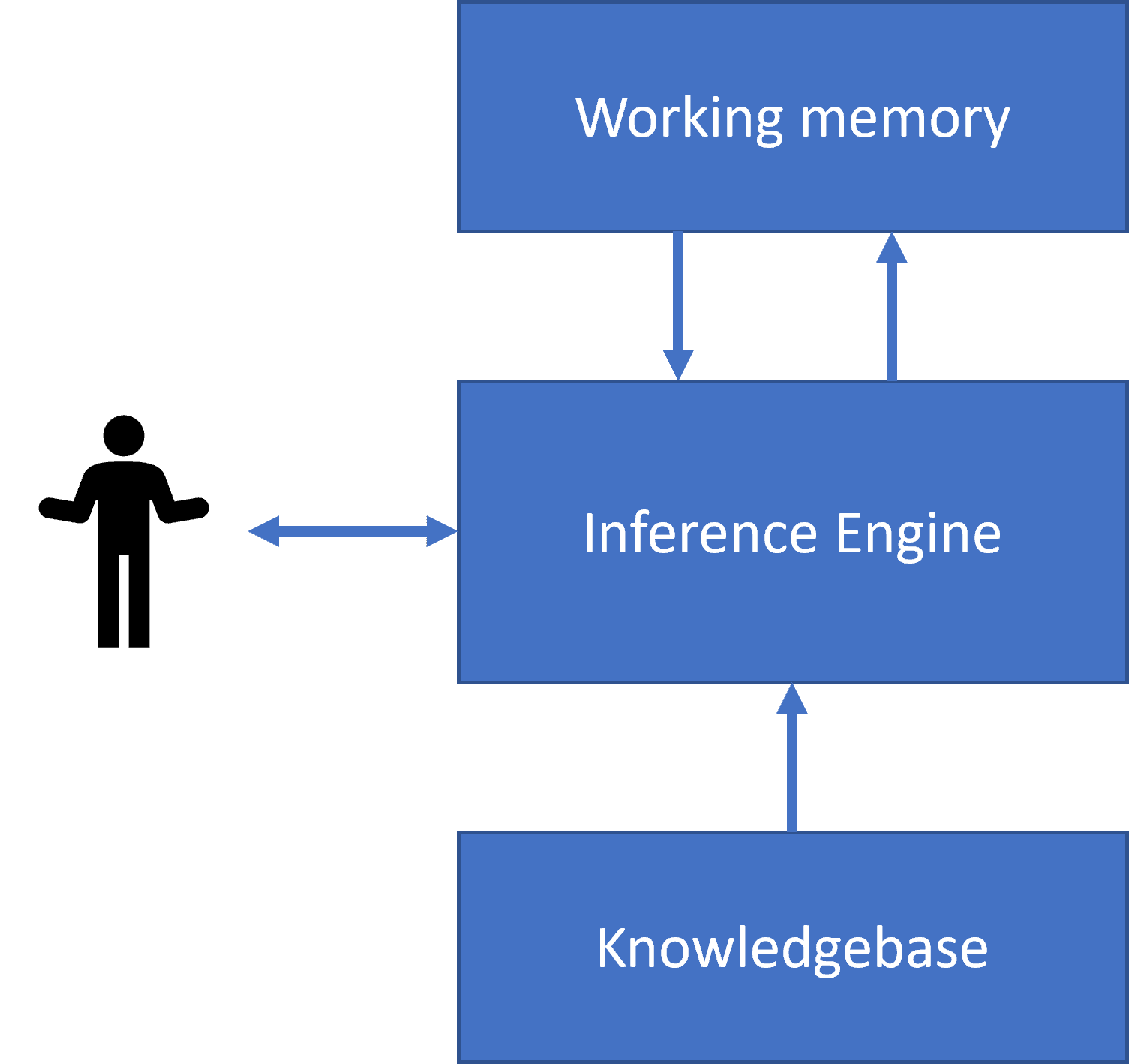 |
|---|---|
| ساختار سادهشدهی یک سامانهی عصبی انسانی | معماری یک سامانهی مبتنی بر دانش |
سیستمهای خبره به شیوهی سیستم استدلال انسانی طراحی شدهاند، که شامل حافظهی کوتاهمدت و حافظهی بلندمدت میباشد. به همین ترتیب، در سیستمهای مبتنی بر دانش، ما اجزای زیر را شناسایی میکنیم:
- حافظهی مسئله: شامل دانش دربارهی مسئلهای است که در حال حاضر در حال حل شدن است، مانند دمای بدن یا فشار خون یک بیمار، اینکه آیا او التهاب دارد یا خیر و غیره. این دانش همچنین به عنوان دانش ایستا شناخته میشود، زیرا شامل یک تصویر لحظهای از آنچه که ما در حال حاضر در مورد مسئله میدانیم - به اصطلاح وضعیت مسئله - است.
- پایگاه دانش: نشاندهندهی دانش بلندمدت در مورد یک حوزهی مسئله است. این دانش به صورت دستی از کارشناسان انسانی استخراج میشود و از مشاوره به مشاوره تغییر نمیکند. از آنجا که به ما امکان میدهد از یک وضعیت مسئله به وضعیت دیگر حرکت کنیم، به آن دانش پویا نیز گفته میشود.
- موتور استنتاج: کل فرآیند جستجو در فضای وضعیت مسئله را هماهنگ میکند و در صورت لزوم از کاربر سؤال میکند. این موتور همچنین مسئول یافتن قوانین مناسب برای اعمال در هر حالت است.
به عنوان مثال، سیستم خبرهی زیر را برای تعیین یک حیوان بر اساس خصوصیات فیزیکی آن در نظر بگیریم:
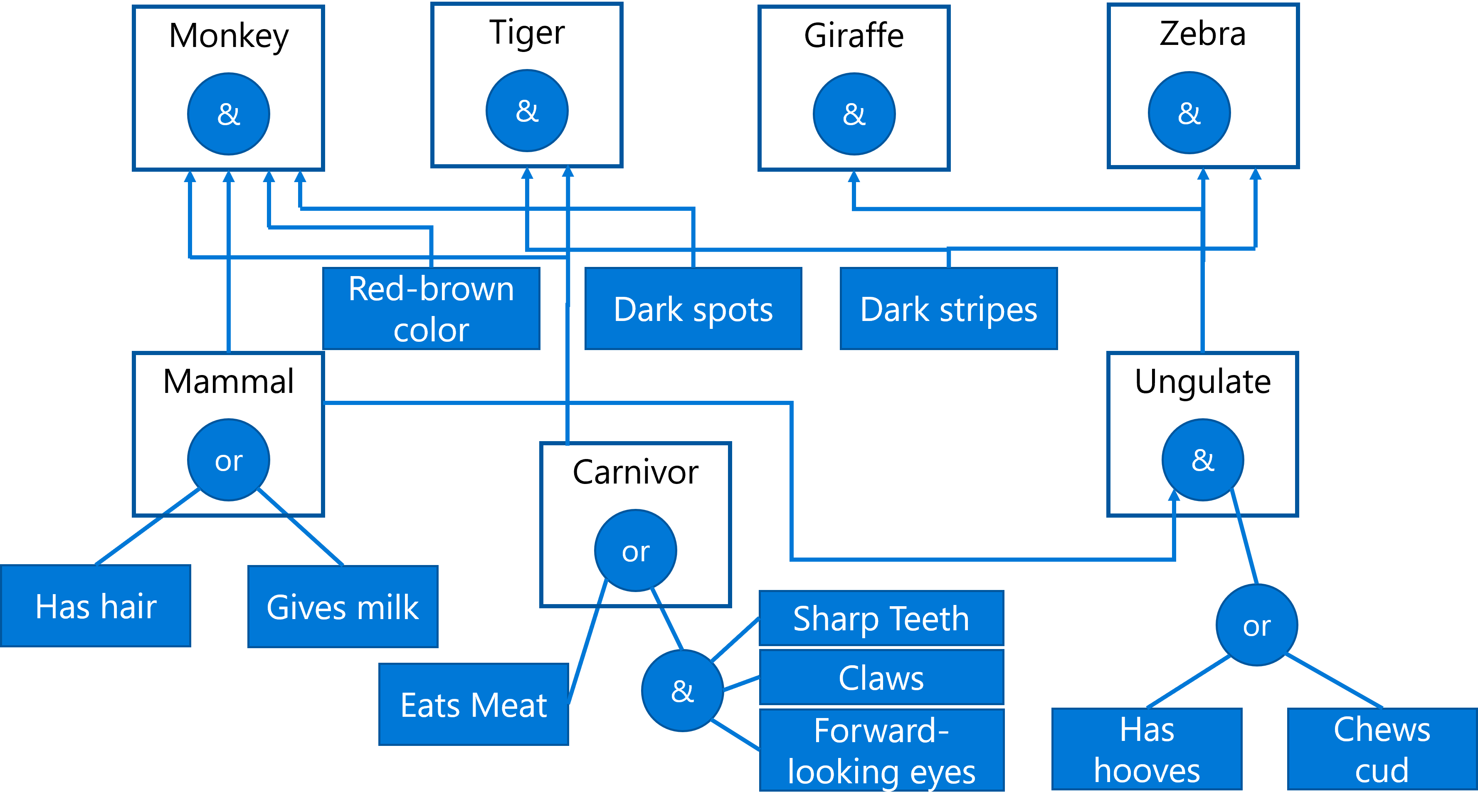
تصویر از دیمیتری ساشنیکوف
این نمودار با عنوان درخت AND-OR شناخته میشود و نمایشی گرافیکی از مجموعهای از قوانین تولید است. ترسیم چنین درختی در آغاز فرآیند استخراج دانش از کارشناس، سودمند خواهد بود. برای بازنمایی دانش در محیط رایانه، بهرهگیری از قوانین، مناسبتر و کارآمدتر است:
IF the animal eats meat
OR (animal has sharp teeth
AND animal has claws
AND animal has forward-looking eyes
)
THEN the animal is a carnivore
شایان توجه است که هر شرط در سمت چپ قاعده و عمل، اساساً سهتاییهای شیء-صفت-مقدار (OAV) میباشند. حافظهی کاری شامل مجموعهای از سهتاییهای OAV است که به مسئلهای که در حال حاضر در حال حل شدن است، مربوط میشود. یک موتور قواعد به دنبال قواعدی میگردد که شرط آنها برآورده شده باشد و آنها را اعمال میکند و یک سهتایی دیگر به حافظهی کاری اضافه میکند.
✅ درخت AND-OR خود را در مورد موضوعی که مورد علاقهتان است، طراحی نمایید!
استنتاج رو به جلو در مقابل استنتاج رو به عقب
فرآیندی که در بالا شرح داده شد، استنتاج رو به جلو نامیده میشود. این فرآیند با برخی دادههای اولیه در مورد مسئله موجود در حافظهی کاری آغاز میشود و سپس حلقه استدلال زیر را اجرا میکند:
- اگر صفت هدف در حافظهی کاری موجود باشد، فرآیند متوقف شده و نتیجه ارائه میگردد.
- به دنبال تمام قواعدی بگردید که شرط آنها در حال حاضر برآورده شده است تا مجموعهی قواعد در تعارض را به دست آورید.
- حل تعارض را انجام دهید و یک قاعده را که در این مرحله اجرا خواهد شد، انتخاب کنید. استراتژیهای حل تعارض مختلفی میتواند وجود داشته باشد:
- اولین قاعده قابل اجرا در پایگاه دانش را انتخاب کنید.
- یک قاعده تصادفی را انتخاب کنید.
- یک قاعده خاصتر را انتخاب کنید، یعنی قاعدهای که بیشترین شرایط را در "سمت چپ" (LHS) برآورده میکند.
- قاعده انتخاب شده را اعمال کنید و قطعهی جدیدی از دانش را به وضعیت مسئله اضافه کنید.
- از مرحله 1 تکرار کنید.
با این وجود، در برخی موارد ممکن است لازم باشد با دانشی ناچیز درباره مسئله آغاز کنیم و پرسشهایی مطرح نماییم که ما را در رسیدن به نتیجه یاری رساند. برای نمونه، در هنگام انجام تشخیص پزشکی، معمولاً پیش از شروع تشخیص بیمار، تمام تحلیلهای پزشکی را از پیش انجام نمیدهیم. بلکه تمایل داریم هنگام نیاز به تصمیمگیری، تحلیلها را به انجام برسانیم.
این فرآیند را میتوان با استفاده از استنتاج رو به عقب مدلسازی نمود. این فرآیند توسط هدف - مقدار صفتی که در پی یافتن آن هستیم - هدایت میشود:
- تمامی قواعدی را برگزینید که میتوانند مقدار هدف را به ما ارائه دهند (یعنی با هدف در RHS ("سمت راست")) - یک مجموعه در تعارض
- اگر هیچ قاعدهای برای این صفت وجود نداشته باشد، یا قاعدهای موجود باشد که بیان کند باید مقدار را از کاربر جویا شویم - از کاربر پرسش نمایید، در غیر این صورت:
- از استراتژی حل تعارض برای انتخاب یک قاعده که به عنوان فرضیه استفاده خواهیم کرد، بهره بگیرید - سعی خواهیم کرد آن را به اثبات برسانیم
- به صورت بازگشتی فرآیند را برای تمامی صفات در LHS قاعده تکرار کنید و سعی کنید آنها را به عنوان اهداف به اثبات برسانید
- اگر در هر مرحلهای فرآیند با شکست مواجه شد - از قاعده دیگری در مرحله 3 استفاده نمایید.
✅ در چه موقعیتهایی استنتاج رو به جلو مناسبتر است؟ در مورد استنتاج رو به عقب چطور؟
پیادهسازی سامانههای متخصص
سامانههای متخصص را میتوان با بهرهگیری از ابزارهای گوناگونی پیادهسازی نمود:
- برنامهنویسی مستقیم آنها با استفاده از یک زبان برنامهنویسی سطح بالا. این رویکرد، بهترین گزینه محسوب نمیشود، چرا که مزیت اصلی یک سامانه مبتنی بر دانش، تفکیک دانش از استنتاج است و به طور بالقوه، یک کارشناس در حوزه مسئله باید قادر باشد قوانین را بدون نیاز به درک جزئیات فرآیند استنتاج، تدوین نماید.
- استفاده از پوسته سامانههای متخصص، به معنای به کارگیری یک سامانه که به طور خاص برای انباشته شدن با دانش، با استفاده از برخی زبانهای بازنمایی دانش طراحی شده است.
🖊 تمرین: استنتاج حیوانات
برای مشاهده مثالی از پیادهسازی سیستم خبره با استنتاج رو به جلو و عقب، به Animals.ipynb مراجعه نمایید.
توجه: این مثال بسیار ساده است و تنها ایدهای از نحوه عملکرد یک سیستم خبره را ارائه میدهد. هنگامی که شروع به ایجاد چنین سیستمی میکنید، تنها زمانی که به تعداد مشخصی از قوانین (حدود 200+) برسید، رفتار هوشمندانه از آن مشاهده خواهید کرد. در برخی مواقع، قوانین بسیار پیچیده میشوند و نمیتوان همه آنها را در ذهن نگه داشت، و در این مرحله ممکن است از خود بپرسید که چرا یک سیستم تصمیمات خاصی میگیرد. با این حال، ویژگی مهم سیستمهای مبتنی بر دانش این است که همیشه میتوانید دقیقاً توضیح دهید که چگونه هر یک از تصمیمات گرفته شده است.
هستیشناسی و وب معنایی
در اواخر قرن بیستم، ابتکاری برای استفاده از بازنمایی دانش جهت حاشیه نویسی منابع اینترنتی وجود داشت، به طوری که امکان یافتن منابع مطابق با پرس و جوهای بسیار خاص فراهم میشد. این حرکت وب معنایی نامیده شد و به چندین مفهوم متکی بود:
- یک بازنمایی دانش ویژه بر اساس منطق توصیفی (DL). این شبیه به بازنمایی دانش چارچوب است، زیرا سلسله مراتبی از اشیاء با خواص ایجاد میکند، اما دارای معناشناسی منطقی رسمی و استنتاج است. یک خانواده کامل از DLها وجود دارد که بین بیان و پیچیدگی الگوریتمی استنتاج تعادل ایجاد میکنند.
- بازنمایی دانش توزیع شده، جایی که همه مفاهیم با یک شناسه URI جهانی نشان داده میشوند و امکان ایجاد سلسله مراتب دانش را در اینترنت فراهم میکند.
- یک خانواده از زبانهای مبتنی بر XML برای توصیف دانش: RDF (چارچوب توصیف منابع)، RDFS (RDF Schema)، OWL (زبان وب هستی شناسی).
یک مفهوم اصلی در وب معنایی، مفهوم هستی شناسی است. این به یک مشخصه صریح از یک دامنه مشکل با استفاده از برخی بازنماییهای دانش رسمی اشاره دارد. سادهترین هستیشناسی میتواند فقط یک سلسله مراتب از اشیاء در یک دامنه مشکل باشد، اما هستیشناسیهای پیچیدهتر شامل قوانینی میشوند که میتوان از آنها برای استنتاج استفاده کرد.
در وب معنایی، همه بازنماییها بر اساس سهتایی هستند. هر شی و هر رابطه به طور منحصر به فرد توسط URI شناسایی میشود. به عنوان مثال، اگر بخواهیم این واقعیت را بیان کنیم که این برنامه درسی هوش مصنوعی در 1 ژانویه 2022 توسط دیمیتری سوشنیکوف توسعه یافته است، در اینجا سهتاییهایی هستند که میتوانیم استفاده کنیم:
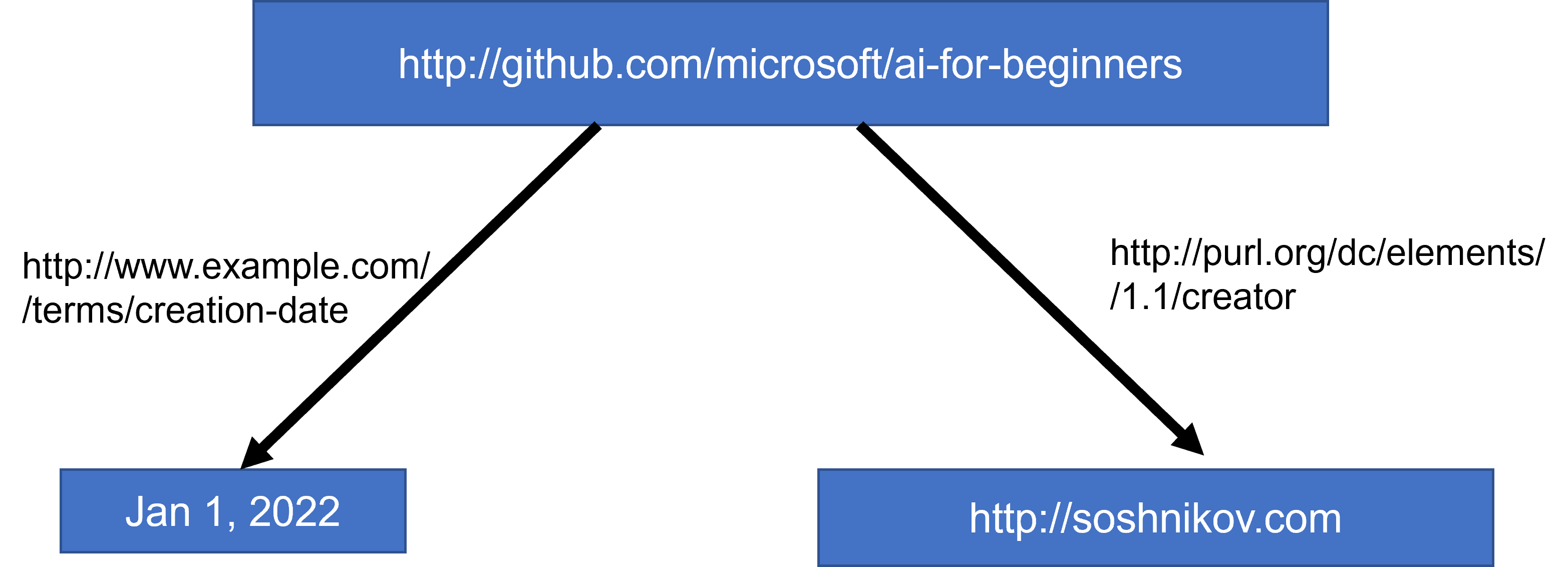
http://github.com/microsoft/ai-for-beginners http://www.example.com/terms/creation-date “Jan 13, 2007”
http://github.com/microsoft/ai-for-beginners http://purl.org/dc/elements/1.1/creator http://soshnikov.com
✅ در این قسمت، http://www.example.com/terms/creation-date و http://purl.org/dc/elements/1.1/creator نمونههایی از URIهای شناخته شده و جهانی پذیرفته شده برای بیان مفاهیم خالق و تاریخ ایجاد هستند.
در یک مورد پیشرفتهتر، اگر قصد تعریف لیستی از خالقان را داشته باشیم، میتوانیم از برخی ساختارهای دادهای که در RDF تعریف شدهاند، استفاده نماییم.
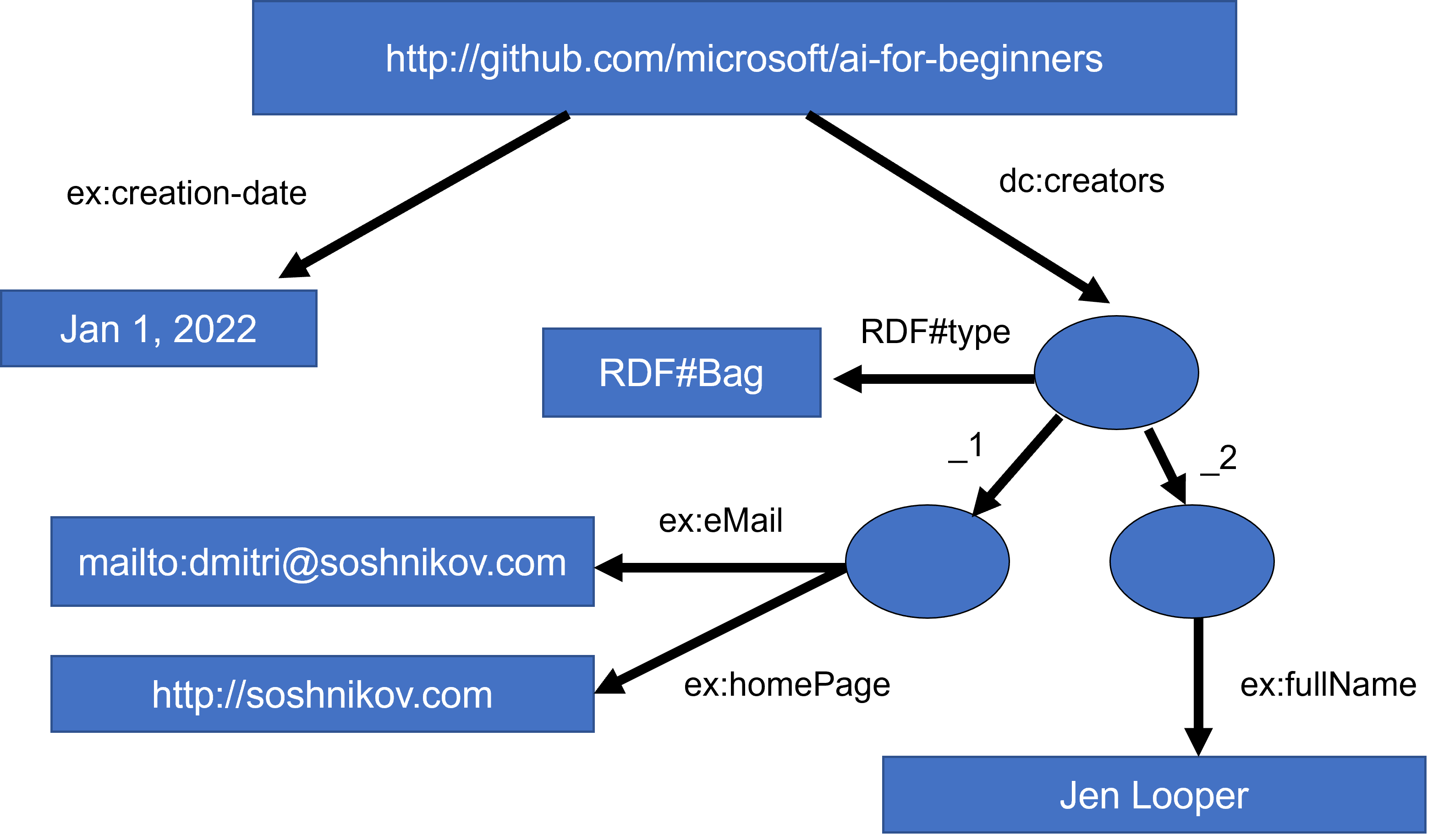
نمودارهای فوق توسط دیمیتری سوشنکوف طراحی شدهاند.
گرچه موفقیت موتورهای جستجو و تکنیکهای پردازش زبان طبیعی، که امکان استخراج دادههای ساختاریافته از متن را فراهم میکنند، تا حدودی پیشرفت در ساخت وب معنایی را کند نمود، اما در برخی زمینهها همچنان تلاشهای قابل توجهی برای حفظ هستیشناسیها و پایگاههای دانش وجود دارد. چند پروژه قابل توجه در این زمینه عبارتند از:
- ویکیداده مجموعهای از پایگاههای دانش قابل خواندن توسط ماشین است که با ویکیپدیا مرتبط هستند. بیشتر دادهها از InfoBoxes ویکیپدیا، که قطعات محتوای ساختاریافته داخل صفحات ویکیپدیا هستند، استخراج میشوند. شما میتوانید ویکیداده را با استفاده از SPARQL، یک زبان پرسوجوی ویژه برای وب معنایی، مورد پرسوجو قرار دهید. به عنوان نمونه، پرسوجوی زیر رایجترین رنگ چشمها در میان انسانها را نمایش میدهد:
#defaultView:BubbleChart
SELECT ?eyeColorLabel (COUNT(?human) AS ?count)
WHERE
{
?human wdt:P31 wd:Q5. # human instance-of homo sapiens
?human wdt:P1340 ?eyeColor. # human eye-color ?eyeColor
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }
}
GROUP BY ?eyeColorLabel
- DBpedia پروژهای مشابه با ویکیداده است که تلاش میکند دادههای ساختاریافته را از ویکیپدیا استخراج کند.
✅ چنانچه تمایل به آزمایش ساخت هستیشناسیهای شخصی یا باز کردن هستیشناسیهای موجود دارید، یک ویرایشگر هستیشناسی بصری کارآمد به نام Protégé وجود دارد. شما میتوانید این نرمافزار را دانلود کرده یا به صورت آنلاین از آن استفاده نمایید.
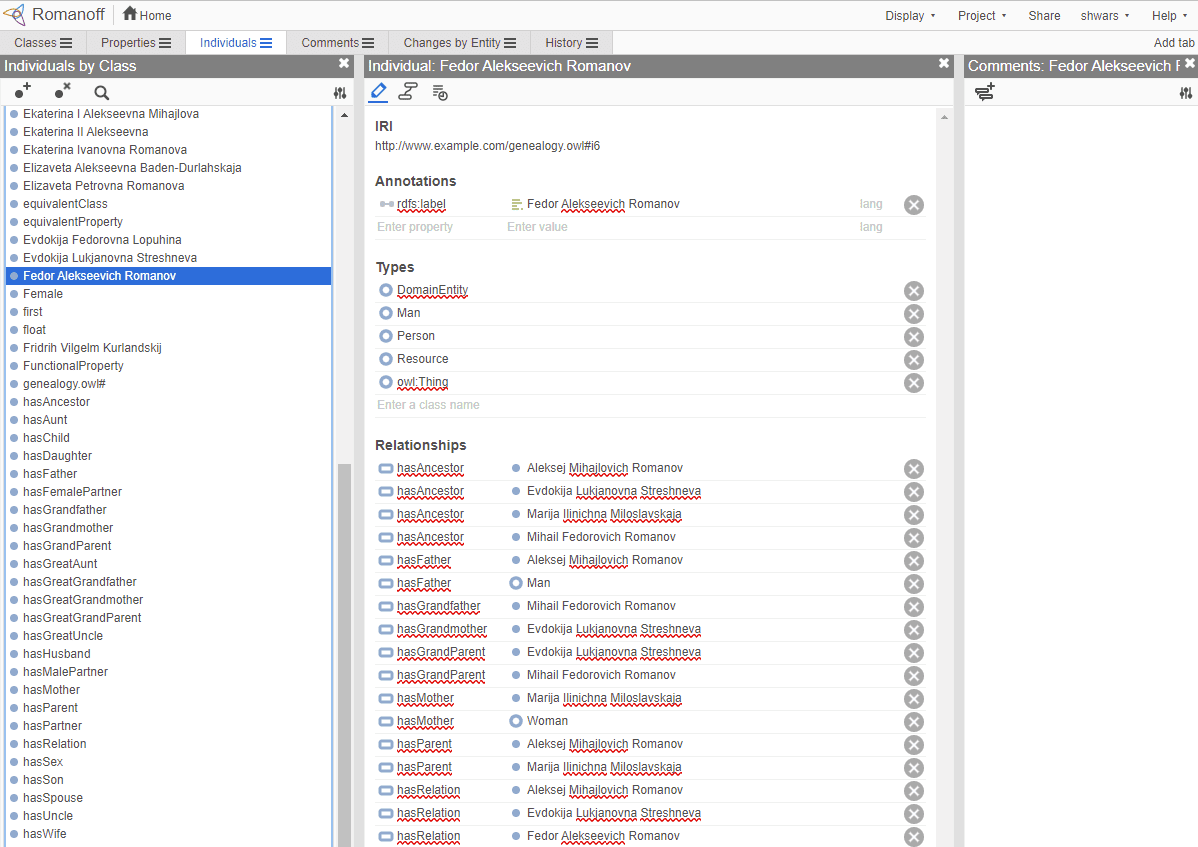
تصویر فوق، ویرایشگر وب Protégé را نشان میدهد که با هستیشناسی خانواده رومانوف باز شده است. این تصویر توسط دیمیتری سوشنکوف گرفته شده است.
✍️ تمرین: هستیشناسی خانوادگی
برای مشاهده یک نمونه از کاربرد تکنیکهای وب معنایی در استدلال پیرامون روابط خانوادگی، به FamilyOntology.ipynb مراجعه فرمایید. در این تمرین، ما یک شجرهنامه را که در قالب رایج GEDCOM ارائه شده است، به همراه یک هستیشناسی از روابط خانوادگی، دریافت نموده و یک گراف از تمام روابط خانوادگی برای یک مجموعه مشخص از افراد ایجاد میکنیم.
گراف مفهومی مایکروسافت
در بسیاری از موارد، هستیشناسیها با دقت و به صورت دستی ایجاد میشوند. با این حال، امکان استخراج هستیشناسیها از دادههای غیرساختاریافته، مانند متون زبان طبیعی، نیز وجود دارد.
یکی از این تلاشها توسط مایکروسافت ریسرچ صورت گرفته و منجر به ایجاد گراف مفهومی مایکروسافت شده است.
این گراف، مجموعهای وسیع از موجودیتها را شامل میشود که با استفاده از رابطه ارثبری is-a گروهبندی شدهاند. این گراف، امکان پاسخ به سوالاتی مانند "مایکروسافت چیست؟" را فراهم میکند - پاسخ چیزی شبیه به "یک شرکت با احتمال 0.87 و یک برند با احتمال 0.75" خواهد بود.
گراف مفهومی مایکروسافت به صورت REST API یا یک فایل متنی بزرگ قابل دانلود که تمام جفتهای موجودیت را فهرست میکند، در دسترس میباشد.
✍️ تمرین: گراف مفهومی
برای مشاهده چگونگی استفاده از گراف مفهومی مایکروسافت جهت گروهبندی مقالات خبری در چندین دسته، نوتبوک MSConceptGraph.ipynb را امتحان کنید.
نتیجهگیری
امروزه، هوش مصنوعی اغلب به عنوان مترادفی برای یادگیری ماشین یا شبکههای عصبی در نظر گرفته میشود. با این حال، یک انسان همچنین استدلال صریحی را نشان میدهد که در حال حاضر توسط شبکههای عصبی مدیریت نمیشود. در پروژههای دنیای واقعی، استدلال صریح هنوز برای انجام وظایفی که نیاز به توضیحات دارند یا قادر به اصلاح رفتار سیستم به روشی کنترلشده هستند، استفاده میشود.
🚀 چالش
در نوتبوک هستیشناسی خانواده مرتبط با این درس، فرصتی برای آزمایش با سایر روابط خانوادگی وجود دارد. سعی کنید ارتباطات جدیدی بین افراد در شجرهنامه کشف کنید.
مرور و خودآموزی
در اینترنت تحقیق کنید تا زمینههایی را کشف کنید که انسانها سعی کردهاند دانش را کمیسازی و کدگذاری کنند. نگاهی به طبقهبندی Bloom بیندازید و به گذشته برگردید تا یاد بگیرید که انسانها چگونه سعی کردند دنیای خود را درک کنند. کار Linnaeus را برای ایجاد یک طبقهبندی از ارگانیسمها بررسی کنید و نحوه ایجاد روشی برای توصیف و گروهبندی عناصر شیمیایی توسط دیمیتری مندلیف را مشاهده کنید. چه نمونههای جالب دیگری میتوانید پیدا کنید؟
تکلیف: یک هستیشناسی بسازید