چارچوبهای شبکه عصبی
همانطور که پیشتر آموختیم، برای آموزش کارآمد شبکههای عصبی، دو اقدام ضروری است:
- کار با تانسورها، مانند انجام عملیات ضرب، جمع و محاسبه توابعی نظیر سیگموئید یا سافتمکس
- محاسبه گرادیان تمام عبارات، جهت انجام بهینهسازی گرادیان نزولی
اگرچه کتابخانه numpy قادر به انجام بخش نخست است، اما برای محاسبه گرادیان به یک سازوکار نیاز داریم. در چارچوبی که توسعه دادیم در بخش قبلی، ناگزیر بودیم تمامی توابع مشتق را به صورت دستی در متد backward برنامهریزی کنیم، که وظیفه پسانتشار را بر عهده دارد. در حالت ایدهآل، یک چارچوب باید قابلیت محاسبه گرادیان هر عبارتی را که میتوانیم تعریف کنیم، فراهم آورد.
نکته مهم دیگر، توانایی انجام محاسبات بر روی GPU یا هر واحد محاسباتی تخصصی دیگری، مانند TPU، است. آموزش شبکه عصبی عمیق نیازمند حجم بالایی از محاسبات است و توانایی موازیسازی این محاسبات بر روی GPU از اهمیت بالایی برخوردار است.
✅ اصطلاح "parallelize" به معنای توزیع محاسبات بر روی چندین دستگاه به صورت همزمان است.
در حال حاضر، دو چارچوب رایج و محبوب در حوزه شبکههای عصبی، TensorFlow و PyTorch میباشند. هر دو چارچوب، یک رابط برنامهنویسی کاربردی (API) سطح پایین برای کار با تانسورها در پردازنده مرکزی (CPU) و پردازنده گرافیکی (GPU) ارائه میدهند. علاوه بر API سطح پایین، یک API سطح بالاتر به نام Keras برای TensorFlow و PyTorch Lightning برای PyTorch وجود دارد.
| API سطح پایین | TensorFlow | PyTorch |
|---|---|---|
| API سطح بالا | Keras | PyTorch Lightning |
APIهای سطح پایین در هر دو چارچوب، امکان ایجاد گرافهای محاسباتی را فراهم میآورند. این گراف، نحوه محاسبه خروجی (معمولاً تابع زیان) با پارامترهای ورودی داده شده را تعریف میکند و میتواند برای محاسبه بر روی GPU، در صورت موجود بودن، ارسال شود. همچنین، توابعی برای مشتقگیری از این گراف محاسباتی و محاسبه گرادیانها وجود دارد که میتوان از آنها برای بهینهسازی پارامترهای مدل استفاده کرد.
APIهای سطح بالا، شبکههای عصبی را به عنوان یک توالی از لایهها در نظر میگیرند و ساخت بیشتر شبکههای عصبی را به مراتب آسانتر میسازند. آموزش مدل معمولاً نیازمند آمادهسازی دادهها و سپس فراخوانی یک تابع fit برای انجام کار است.
API سطح بالا به شما امکان میدهد تا شبکههای عصبی معمولی را به سرعت و بدون نگرانی در مورد بسیاری از جزئیات بسازید. در مقابل، API سطح پایین کنترل بیشتری بر فرآیند آموزش ارائه میدهد و به همین دلیل در تحقیقات، زمانی که با معماریهای جدید شبکه عصبی سروکار دارید، بسیار مورد استفاده قرار میگیرد.
همچنین شایان ذکر است که میتوانید از هر دو API به صورت ترکیبی استفاده کنید. به عنوان مثال، میتوانید معماری لایه شبکه خود را با استفاده از API سطح پایین توسعه دهید و سپس از آن در شبکه بزرگتری که با API سطح بالا ساخته و آموزش داده شده است، استفاده کنید. همچنین میتوانید یک شبکه را با استفاده از API سطح بالا به عنوان یک توالی از لایهها تعریف کنید و سپس از حلقه آموزشی سطح پایین خود برای انجام بهینهسازی استفاده کنید. هر دو API از همان مفاهیم اساسی زیربنایی استفاده میکنند و برای کار کردن به صورت هماهنگ با یکدیگر طراحی شدهاند.
یادگیری
در این دوره، ما بیشتر محتوا را برای هر دو چارچوب PyTorch و TensorFlow ارائه میدهیم. شما میتوانید چارچوب مورد نظر خود را انتخاب کنید و تنها نوتبوکهای مربوطه را بررسی کنید. اگر در انتخاب چارچوب مردد هستید، میتوانید برخی از بحثها را در اینترنت در مورد PyTorch در مقابل TensorFlow مطالعه کنید. همچنین میتوانید نگاهی به هر دو چارچوب بیندازید تا درک بهتری داشته باشید.
در صورت امکان، ما از APIهای سطح بالا برای سادگی استفاده خواهیم کرد. با این حال، ما معتقدیم که درک نحوه عملکرد شبکههای عصبی از پایه مهم است، بنابراین در ابتدا با API سطح پایین و تانسورها کار میکنیم. با این حال، اگر میخواهید سریع شروع کنید و نمیخواهید زمان زیادی را برای یادگیری این جزئیات صرف کنید، میتوانید آنها را رد کنید و مستقیماً به نوتبوکهای API سطح بالا مراجعه کنید.
✍️ تمرینات: چارچوبها
یادگیری خود را در نوتبوکهای زیر ادامه دهید:
| API سطح پایین | TensorFlow+Keras Notebook | PyTorch |
|---|---|---|
| API سطح بالا | Keras | PyTorch Lightning |
پس از تسلط بر چارچوبها، اجازه دهید مفهوم بیش برازش را مرور کنیم.
بیش برازش (Overfitting)
بیش برازش یک مفهوم بسیار مهم در یادگیری ماشین است و درک صحیح آن بسیار حائز اهمیت است.
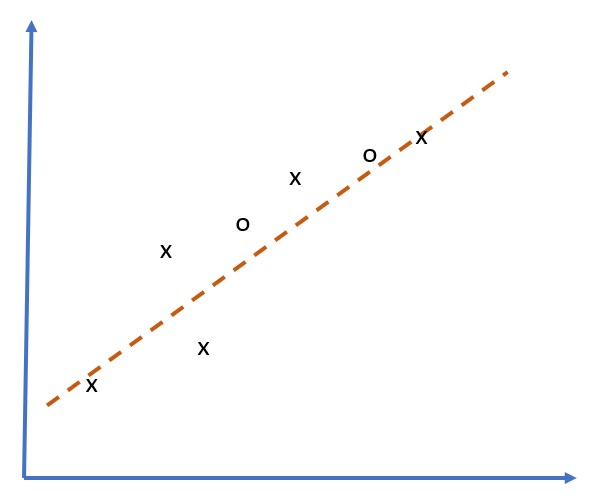
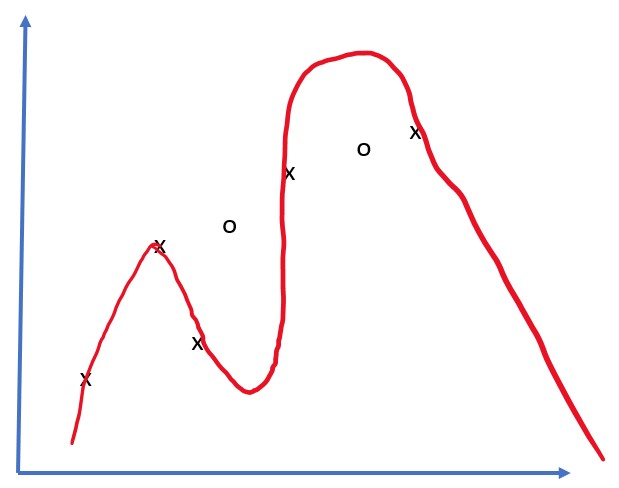
مسئله تقریب ۵ نقطه (که در نمودارهای زیر با x نشان داده شده است) را در نظر بگیرید:
 |  |
|---|---|
| مدل خطی، ۲ پارامتر | مدل غیرخطی، ۷ پارامتر |
| خطای آموزش = ۵.۳ | خطای آموزش = ۰ |
| خطای اعتبارسنجی = ۵.۱ | خطای اعتبارسنجی = ۲۰ |
- در سمت چپ، یک تقریب خطی مناسب را مشاهده میکنیم. از آنجایی که تعداد پارامترها متناسب است، مدل ایده پشت توزیع نقاط را به درستی درک میکند.
- در سمت راست، مدل بیش از حد قدرتمند است. از آنجایی که ما فقط ۵ نقطه داریم و مدل ۷ پارامتر دارد، میتواند به گونهای تنظیم شود که از تمام نقاط عبور کند و خطای آموزش را به صفر برساند. با این حال، این باعث میشود مدل الگوی صحیح پشت دادهها را درک نکند و در نتیجه خطای اعتبارسنجی بسیار بالا باشد.
بسیار مهم است که بین غنای مدل (تعداد پارامترها) و تعداد نمونههای آموزشی تعادل درستی برقرار شود.
چرا بیش برازش رخ میدهد
- دادههای آموزشی ناکافی است
- مدل بیش از حد پیچیده و قدرتمند است
- دادههای ورودی دارای نویز زیادی هستند
چگونه بیش برازش را تشخیص دهیم
همانطور که از نمودار بالا مشاهده میکنید، بیش برازش را میتوان با خطای آموزش بسیار پایین و خطای اعتبارسنجی بالا تشخیص داد. معمولاً در طول آموزش، خطای آموزش و اعتبارسنجی شروع به کاهش میکنند، و سپس در یک نقطه مشخص، خطای اعتبارسنجی ممکن است کاهش را متوقف کند و شروع به افزایش کند. این یک نشانه بیش برازش است و نشان میدهد که احتمالاً باید آموزش را در این نقطه متوقف کنیم (یا حداقل یک نسخه از مدل تهیه کنیم).
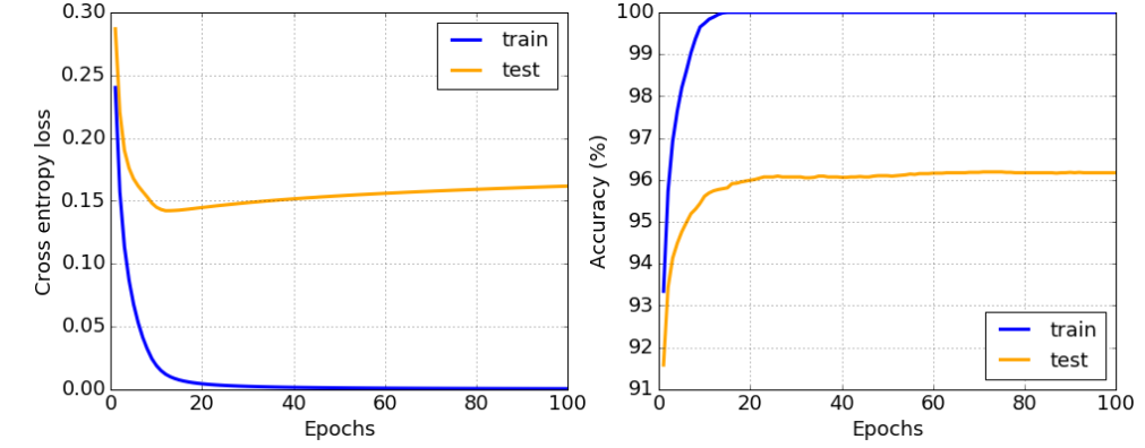
چگونه از بیش برازش جلوگیری کنیم
اگر مشاهده کردید که بیش برازش رخ میدهد، میتوانید یکی از کارهای زیر را انجام دهید:
- مقدار دادههای آموزشی را افزایش دهید
- پیچیدگی مدل را کاهش دهید
- از برخی تکنیکهای منظمسازی، مانند Dropout، که بعداً بررسی خواهیم کرد، استفاده کنید.
بیش برازش و مصالحه بایاس-واریانس
بیش برازش در واقع یک مورد از یک مشکل عمومیتر در آمار به نام مصالحه بایاس-واریانس است. اگر منابع احتمالی خطا در مدل خود را در نظر بگیریم، میتوانیم دو نوع خطا را مشاهده کنیم:
- خطاهای بایاس به دلیل عدم توانایی الگوریتم ما در درک صحیح رابطه بین دادههای آموزشی ایجاد میشوند. این میتواند ناشی از این واقعیت باشد که مدل ما به اندازه کافی قدرتمند نیست (کم برازش).
- خطاهای واریانس، که به دلیل تقریب نویز در دادههای ورودی به جای رابطه معنادار (بیش برازش) ایجاد میشوند.
در طول آموزش، خطای بایاس کاهش مییابد (زیرا مدل ما یاد میگیرد دادهها را تقریب بزند) و خطای واریانس افزایش مییابد. مهم است که آموزش را متوقف کنیم - یا به صورت دستی (زمانی که بیش برازش را تشخیص میدهیم) یا به صورت خودکار (با معرفی منظمسازی) - تا از بیش برازش جلوگیری کنیم.
نتیجه گیری
در این درس، شما با تفاوتهای میان APIهای گوناگون برای دو چارچوب پرطرفدار هوش مصنوعی، TensorFlow و PyTorch، آشنا شدید. همچنین، به موضوع بسیار مهم "بیش برازش" نیز پرداخته شد.