بررسی و مقایسه مدلهای زبانی بزرگ مختلف
در درس قبلی، مشاهده کردیم که چگونه هوش مصنوعی مولد در حال تغییر چشمانداز فناوری است، نحوه عملکرد مدلهای زبانی بزرگ (LLM) را بررسی نمودیم و دیدیم چگونه یک کسبوکار - همانند استارتاپ ما - میتواند از این مدلها در موارد استفاده خود بهرهبرداری کرده و رشد نماید! در این فصل، هدف ما مقایسه و تحلیل انواع مختلف مدلهای زبانی بزرگ (LLM) به منظور درک مزایا و معایب هر یک از آنها است.
گام بعدی در مسیر استارتاپ ما، بررسی وضعیت کنونی مدلهای زبانی بزرگ و شناسایی مدلهایی است که برای موارد کاربرد ما مناسب میباشند.
مقدمه
این درس شامل موضوعات زیر خواهد بود:
- انواع مختلف مدلهای زبانی بزرگ (LLM) در زمینه کنونی.
- شیوه استقرار یک مدل زبانی بزرگ.
اهداف یادگیری
پس از پایان این درس، شما قادر خواهید بود:
- مدل مناسب برای استفاده خود را انتخاب نمایید.
- درک نمایید چگونه عملکرد مدل خود را آزمایش، تکرار و بهبود بخشید.
- بدانید که چگونه کسبوکارها مدلها را پیادهسازی میکنند.
درک انواع مختلف LLMها
مدلهای LLM میتوانند بر اساس معماری، دادههای آموزشی و کاربردهای آنها به دستهبندیهای مختلفی تقسیم شوند. درک این تفاوتها به ما کمک میکند تا مدل مناسب را برای سناریوهای مختلف انتخاب کنیم و نحوه آزمایش، تکرار و بهبود عملکرد آنها را درک کنیم.
مدلهای LLM دارای انواع مختلفی هستند و انتخاب شما به اهداف مورد نظر، نوع دادهها، میزان هزینهای که تمایل دارید پرداخت کنید و عوامل دیگر وابسته است.
با توجه به اینکه آیا قصد دارید از مدلها برای تولید متن، صدا، ویدئو، تصویر و غیره استفاده نمایید، ممکن است نیاز به انتخاب مدلهای متفاوت داشته باشید.
-
تشخیص صدا و گفتار: برای این منظور، مدلهای نوع Whisper گزینهای مناسب محسوب میشوند، زیرا این مدلها بهطور عمومی طراحی شدهاند و هدف آنها شناسایی گفتار است. این مدلها بر روی دادههای صوتی متنوع آموزش دیده و میتوانند شناسایی گفتار چندزبانه را انجام دهند. برای اطلاعات بیشتر در مورد مدلهای نوع Whisper اینجا کلیک کنید.
-
تولید تصویر: برای تولید تصویر، DALL-E و Midjourney از جمله انتخابهای بسیار معروف هستند. برای اطلاعات بیشتر در مورد DALL-E اینجا کلیک کنید و همچنین در فصل 9 این دوره به آن خواهیم پرداخت.
-
تولید متن: اکثر مدلها بهطور خاص برای تولید متن آموزش دیدهاند و گزینههای مختلفی از جمله GPT-3.5 تا GPT-4 در دسترس است. این مدلها با هزینههای متفاوتی ارائه میشوند، بهطوری که GPT-4 گرانترین گزینه محسوب میشود.
-
چندوجهی: اگر به دنبال پشتیبانی از چند نوع داده در ورودی و خروجی هستید، ممکن است بخواهید به مدلهایی مانند gpt-4-turbo یا gpt-4o-vision که آخرین انتشارهای مدلهای OpenAI هستند، نگاهی بیندازید. این مدلها قادر به ترکیب پردازش زبان طبیعی با درک بصری بوده و امکان تعامل از طریق واسطهای چندوجهی را فراهم میآورند.
انتخاب یک مدل به این معناست که شما برخی از قابلیتهای پایه را دریافت میکنید، اما ممکن است این برای برآورده ساختن نیازهای شما کافی نباشد. بسیاری اوقات شما دادههای خاص شرکتی دارید که نیاز به انتقال به LLM دارند. گزینههای مختلفی برای نزدیک شدن به این موضوع وجود دارد که در بخشهای آتی بیشتر به آن خواهیم پرداخت.
مدلهای بنیادین در مقابل LLMها
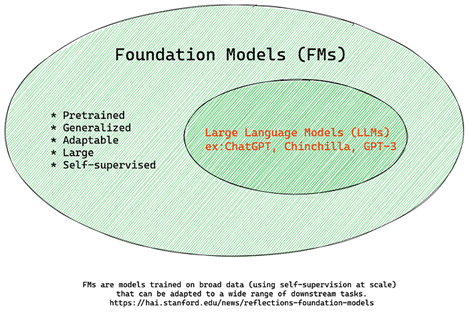
اصطلاح "مدل بنیادین" توسط پژوهشگران دانشگاه استنفورد تعریف شده و به عنوان یک مدل هوش مصنوعی شناسایی میشود که برخی ویژگیها و معیارها را دارا میباشد، از جمله:
- این مدلها با استفاده از روشهای یادگیری بدون نظارت یا یادگیری خودنظارتی آموزش دیدهاند. بدین معنا که آنها بر روی دادههای چندرسانهای بدون برچسب آموزش یافتهاند و نیازی به دادههای دارای علامتگذاری یا برچسبگذاری انسانی در فرآیند آموزش خود ندارند.
- این مدلها معمولاً از ابعاد بسیار بزرگی برخوردارند و بر پایه شبکههای عصبی عمیق آموزش دیدهاند و دارای میلیاردها پارامتر هستند.
- این مدلها به عنوان یک "بنیاد" برای ساخت مدلهای دیگر مورد استفاده قرار میگیرند، به این معنا که میتوانند به عنوان نقطه شروعی برای ایجاد سایر مدلها به کار روند که این کار معمولاً از طریق تنظیم دقیق انجام میشود.
منبع تصویر: Essential Guide to Foundation Models and Large Language Models | by Babar M Bhatti | Medium
برای روشنسازی این تمایز، بیایید ChatGPT را به عنوان نمونهای بررسی کنیم. برای ایجاد نسخه اولیه ChatGPT، مدلی به نام GPT-3.5 به عنوان مدل بنیادین مورد استفاده قرار گرفت. این به این معناست که شرکت OpenAI از دادههای خاصی مربوط به چت برای تولید نسخهای تنظیم شده از GPT-3.5 بهرهبرداری کرده است که در انجام موثر در سناریوهای گفتگو، مانند چتباتها، تخصصیتر شده است.
منبع تصویر: 2108.07258.pdf (arxiv.org)
مدلهای متنباز در مقابل مدلهای اختصاصی
یکی از روشهای دیگر دستهبندی مدلهای LLM بر اساس این است که آیا این مدلها متنباز هستند یا اختصاصی.
مدلهای متنباز به آن دسته از مدلها اطلاق میشود که بهصورت عمومی در دسترس قرار دارند و هر فردی میتواند از آنها بهرهبرداری نماید. این مدلها معمولاً توسط شرکتی که آنها را توسعه داده یا بهوسیله جامعه علمی ارائه میشوند. مزیت این مدلها در این است که قابلیت بازرسی، تغییر و سفارشیسازی برای کاربردهای مختلف در LLM را دارند، لیکن ممکن است همیشه بهینهسازی لازم برای استفاده در پروداکشن را نداشته باشند و بهاندازهی مدلهای اختصاصی کارایی نداشته باشند. علاوه بر این، تأمین مالی مدلهای متنباز ممکن است محدود باشد و ممکن است بهطور بلندمدت حفظ نشوند یا با جدیدترین تحقیقات بهروز نشوند. از جمله مدلهای متنباز مشهور میتوان به آلپاکا، بلوم و LLaMA اشاره کرد.
مدلهای اختصاصی، مدلی هستند که متعلق به یک شرکت خاص بوده و بهصورت عمومی در دسترس قرار نمیگیرند. این مدلها معمولاً برای استفاده در پروداکشن بهینهسازی شدهاند. با این وجود، آنها اجازه بازرسی، تغییر یا سفارشیسازی در کاربردهای مختلف را نمیدهند. همچنین، این مدلها ممکن است همیشه بهصورت رایگان در دسترس نباشند و برای استفاده از آنها نیاز به اشتراک یا پرداخت هزینه وجود داشته باشد. علاوه بر این، کاربران بر دادههایی که برای آموزش مدل به کار گرفته میشوند، کنترل نداشته و به همین جهت باید به مالک مدل اعتماد نمایند تا به حفظ حریم خصوصی دادهها و استفاده مسئولانه از هوش مصنوعی متعهد باشد. نمونههایی از مدلهای اختصاصی مطرح شامل مدلهای OpenAI، گوگل بارد و کلود ۲ میباشد.
بررسی و مقایسه انواع مدلهای LLM: ارائه نشاننده ، تولید تصویر، تولید متن و تولید کد
مدلهای زبانی بزرگ (LLMs) را میتوان بر اساس نوع خروجیای که تولید میکنند، طبقهبندی کرد.
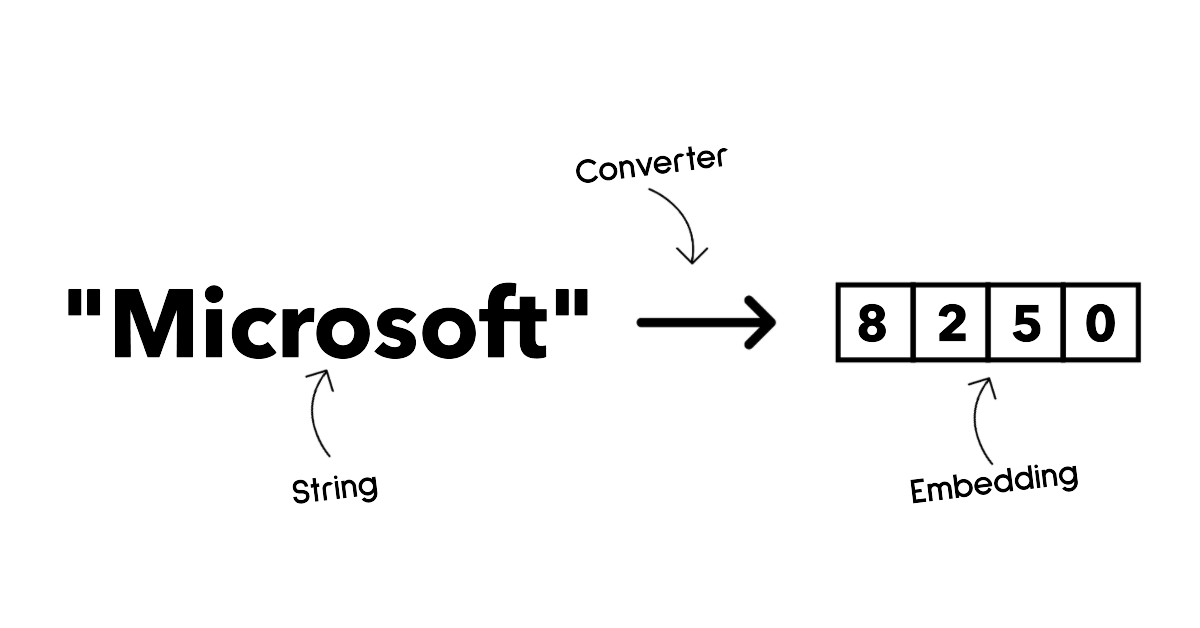
مدلهای نشاننده (Embedding) مجموعهای از الگوریتمها هستند که توانایی تبدیل متن به یک فرم عددی به نام نشاننده را دارند. نوع نشاننده نمایش عددی متن ورودی را فراهم میآورد و به ماشینها کمک میکند تا روابط موجود بین کلمات یا جملات را بهتر درک کنند. همچنین نشانندهها میتوانند به عنوان ورودی برای مدلهای دیگر، همچون مدلهای دستهبندی یا خوشهبندی که عملکرد بهتری روی دادههای عددی دارند، مورد استفاده قرار گیرند. مدلهای نشاننده معمولاً در زمینه یادگیری انتقالی به کار گرفته میشوند، جایی که مدلی برای یک کار جانبی که دادههای فراوانی در دسترس است ایجاد میشود و سپس وزنهای آن مدل (نشانندهها) برای سایر وظایف پاییندستی دوباره به کار میرود. نمونهای از این دسته مدلها، Embeddings OpenAI میباشد.
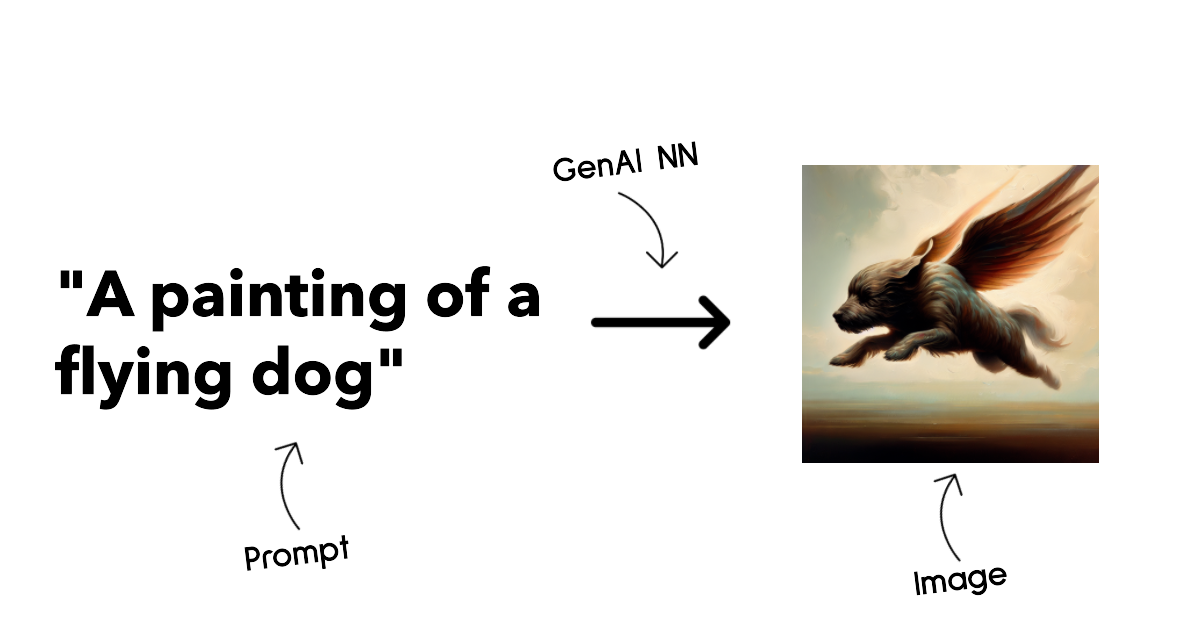
مدلهای تولید تصویر، به الگوریتمهایی اطلاق میشود که قابلیت تولید تصاویر را دارند. این مدلها معمولاً در زمینههای ویرایش تصویر، سنتز تصویر و ترجمه تصویر استفاده میشوند. مدلهای تولید تصویر اغلب بر روی مجموعه دادههای وسیعی از تصاویر، مانند LAION-5B آموزش دیدهاند و قادرند برای تولید تصاویر جدید یا ویرایش تصاویر موجود با استفاده از تکنیکهایی نظیر درونپوشانی، افزایش وضوح و رنگآمیزی به کار گرفته شوند. از جمله مثالهای این دسته میتوان به DALL-E-3 و مدلهای Stable Diffusion اشاره کرد.
مدلهای تولید متن و کد، به الگوریتمهایی اشاره دارند که قابلیت تولید متن یا کد را دارند. این مدلها معمولاً در کاربردهایی نظیر خلاصهسازی متن، ترجمه و پاسخ به سؤالات به کار میروند. مدلهای تولید متن غالباً بر روی مجموعه دادههای گوناگون متنی، مانند BookCorpus آموزش داده میشوند و قادرند برای تولید متن جدید یا پاسخ به سؤالات مورد استفاده قرار گیرند. همچنین، مدلهای تولید کد نظیر CodeParrot معمولاً بر روی مجموعه دادههای بزرگی از کد، مانند GitHub، آموزش دیده و توانایی تولید کد جدید یا اصلاح اشکالات در کدهای موجود را دارا میباشند.
بهبود نتایج LLM
ما در تیم استارتاپ خود به بررسی انواع گوناگون LLMها پرداختیم.
اما چه زمانی باید یک مدل بهینهشده را بهجای استفاده از یک مدل پیشآموزشدیده پرورش دهیم؟ آیا روشهای دیگری برای بهبود عملکرد مدل در بارهای کاری خاص وجود دارد؟
چندین رویکرد وجود دارد که یک کسبوکار میتواند برای دستیابی به نتایج مطلوب خود از LLM بهرهبرداری کند. هنگامی که یک LLM را برای پروداکشن مستقر میسازید، میتوانید انواع مختلف مدلها را با درجات متفاوتی از آموزش انتخاب کنید، که هر یک با سطوح متفاوتی از پیچیدگی، هزینه و کیفیت همراه است. در اینجا به چندین رویکرد مختلف اشاره میشود:
-
مهندسی ورودی با متن زمینهای: ایده این است که هنگام فراخوانی، زمینه کافی فراهم شود تا از دریافت پاسخهای مورد نیاز اطمینان حاصل گردد.
-
تولید تقویتشده با بازیابی (RAG): ممکن است دادههای شما در یک پایگاه داده یا نقطه پایانی وب وجود داشته باشد؛ برای تضمین گنجاندن این دادهها یا زیرمجموعهای از آنها در زمان فراخوانی، میتوانید دادههای مرتبط را بازیابی کرده و بخشی از ورودی کاربر قرار دهید.
-
مدل بهینهشده: در این روش، شما مدل را تحت آموزش بر روی دادههای خود قرار میدهید که منجر به دقت و پاسخگویی بیشتر مدل به نیازهای شما میشود، اما این ممکن است هزینهبر باشد.
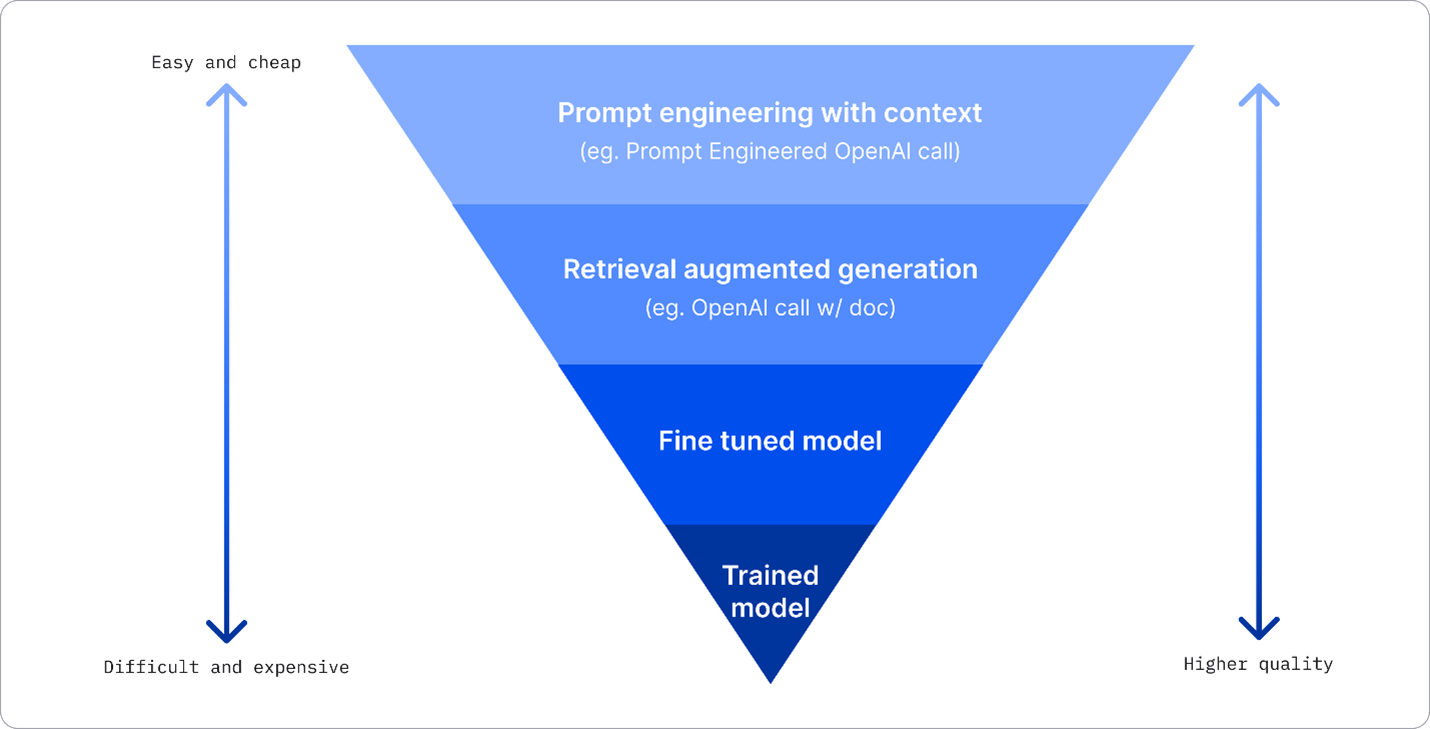
منبع تصویر: چهار راهی که شرکتها LLM را مستقر میکنند | وبلاگ Fiddler AI
مهندسی پرسش (prompt) با زمینه
مدلهای زبانی پیشآموزشدادهشده (LLM) در انجام وظایف عمومی زبان طبیعی بسیار مؤثر عمل میکنند، حتی با استفاده از یک پرسش کوتاه، مانند یک جمله برای تکمیل یا یک سؤال — آنچه که به عنوان یادگیری "صفر-شات" شناخته میشود.
با این حال، هرچه کاربر بتواند درخواست خود را با جزئیات و مثالهای بیشتری قالببندی کند — یعنی زمینه — پاسخ به انتظارات کاربر نزدیکتر و دقیقتر خواهد بود. در این زمینه، اگر پرسش تنها شامل یک مثال باشد، به یادگیری "یک-شات" اشاره میشود و اگر شامل چندین مثال باشد، به یادگیری "Few-Shot" نام برده میشود. مهندسی پرسش با زمینه، بهعنوان مؤثرترین و مقرونبهصرفهترین روش برای آغاز کار محسوب میشود.
تولید تقویتشده با بازیابی (RAG)
مدلهای زبانی دارای محدودیتی هستند که تنها میتوانند از دادههایی که در خلال فرآیند آموزش خود استفاده شدهاند، برای تولید پاسخ استفاده کنند. این بدان معنی است که آنها هیچ اطلاعی از واقعیات پس از فرآیند آموزش خود ندارند و نمیتوانند به اطلاعات غیرعمومی (مانند دادههای شرکتی) دسترسی پیدا کنند.
این معضل را میتوان با استفاده از RAG، تکنیکی که پرسش را با دادههای خارجی به شکل قطعات اسناد تقویت میکند، برطرف نمود. این فرآیند با در نظر گرفتن محدودیتهای طول پرسش انجام میشود.
این تکنیک بهویژه در شرایطی که یک کسبوکار از دادهها، زمان یا منابع کافی برای بهینهسازی یک مدل زبان خاص برخوردار نیست، بسیار مفید است، اما همچنان تمایل به بهبود عملکرد در یک حجم کار مشخص و کاهش ریسکهای تحریف واقعیت یا تولید محتوای مضر دارد.
مدل دقیقشده (Fine-tuned model)
تنظیم دقیق (Fine-tuning) یک فرآیند است که از یادگیری انتقالی بهرهبرداری میکند تا مدل را به یک وظیفه پاییندست سازگار کند یا یک مشکل خاص را حل نماید. بر خلاف یادگیری با تعداد کم نمونه و RAG، این فرآیند منجر به ایجاد یک مدل جدید با وزنها و بایاسهای بهروزشده میشود. این کار مستلزم وجود مجموعهای از نمونههای آموزشی است که شامل یک ورودی (the prompt) و خروجی مرتبط (the completion) آن میباشد.
این رویکرد در صورتی مطلوب است که:
-
استفاده از مدلهای دقیقشده. یک کسبوکار مایل است از مدلهای دقیقشده با قابلیت کمتر (همچون مدلهای embedding) بهرهبرداری کند، به جای مدلهای با عملکرد بالا، که نتیجه آن دستیابی به راهحلی مقرون به صرفه و سریعتر خواهد بود.
-
ملاحظه تأخیر. تأخیر برای یک مورد استفاده خاص حائز اهمیت است، بنابراین امکان استفاده از پرسشهای بسیار طولانی وجود ندارد و همچنین تعداد نمونههایی که باید از مدل یاد گرفته شود با محدودیت طول پیشنهاد سازگار نیست.
-
بهروز نگهداشتن اطلاعات. یک کسبوکار دارای مجموعهای از دادههای باکیفیت و برچسبهای واقعی است و منابع لازم برای بهروزرسانی این دادهها را در طول زمان در اختیار دارد.
مدل آموزشدیده
آموزش یک مدل LLM از ابتدا، بدون تردید، دشوارترین و پیچیدهترین رویکردی است که میتوان اتخاذ نمود و نیازمند مقادیر قابل توجهی از دادهها، منابع متخصص و قدرت محاسباتی مناسب میباشد. این گزینه تنها در شرایطی باید مد نظر قرار گیرد که یک کسبوکار دارای یک مورد استفاده خاص در یک حوزه و مقدار زیادی داده مرتبط با آن حوزه باشد.
🚀 چالش
بیشتر در مورد اینکه چگونه میتوانید از RAG برای کسبوکار خود استفاده کنید، مطالعه کنید.