استفاده مسئولانه از هوش مصنوعی مولد
شگفتزده شدن از هوش مصنوعی، بهویژه هوش مصنوعی مولد، امری آسان است؛ اما لازم است در نظر داشته باشید که چگونه میتوانید از آن بهطور مسئولانه استفاده کنید. شما باید به مسائلی از قبیل چگونگی اطمینان از اینکه خروجی حاصل عادلانه، غیرمضر و در راستای دیگر اصول باشد، فکر کنید. هدف این فصل ارائه زمینه مربوطه، نکات قابل توجه و راهکارهایی برای بهبود استفاده شما از هوش مصنوعی است.
مقدمه
این درس شامل موارد زیر خواهد بود:
- اهمیت اولویت دادن به هوش مصنوعی مسئولانه در زمان توسعه برنامههای هوش مصنوعی مولد.
- اصول اساسی هوش مصنوعی مسئولانه و ارتباط آنها با هوش مصنوعی مولد.
- شیوههای عملیاتیسازی این اصول هوش مصنوعی مسئولانه از طریق استراتژی و ابزارهای مرتبط.
اهداف آموزشی
پس از اتمام این درس، شما قادر خواهید بود:
- اهمیت هوش مصنوعی مسئولانه را در هنگام طراحی و توسعه برنامههای هوش مصنوعی مولد درک نمایید.
- زمان مناسب برای اندیشیدن به اصول اساسی هوش مصنوعی مسئولانه و به کارگیری آنها در فرایند ساخت برنامههای هوش مصنوعی مولد را شناسایی کنید.
- ابزارها و استراتژیهای موجود را جهت عملی ساختن مفهوم هوش مصنوعی مسئولانه بشناسید.
اصول هوش مصنوعی مسئولانه
هیجان نسبت به هوش مصنوعی مولد هرگز به این میزان نبوده است. این هیجان توجه و سرمایهگذاری قابل توجهی را به این حوزه جلب کرده است. اگرچه این موضوع برای افرادی که به دنبال ایجاد محصولات و شرکتهایی با استفاده از هوش مصنوعی مولد هستند، بسیار مثبت است، اما مهم است که بهطور مسئولانه پیش برویم.
در طول این دوره، تمرکز ما بر روی راهاندازی استارتاپ و محصول آموزشی هوش مصنوعیمان خواهد بود. ما از اصول هوش مصنوعی مسئولانه شامل عادلانه بودن، فراگیری، قابلیت اطمینان/ایمنی، امنیت و حریم خصوصی، شفافیت و پاسخگویی استفاده خواهیم کرد. با استفاده از این اصول، به بررسی ارتباط آنها با نحوه استفادهمان از هوش مصنوعی مولد در محصولاتمان خواهیم پرداخت.
چرا باید بر هوش مصنوعی مسئولانه تأکید کنیم
هنگامی که محصولی را طراحی میکنید، اتخاذ رویکردی انسانمحور و در نظر گرفتن منافع کاربران، به دستیابی به بهترین نتایج کمک میکند.
ویژگی منحصر به فرد هوش مصنوعی مولد، قابلیت آن در تولید پاسخها، اطلاعات، راهنماها و محتوای سودمند برای کاربران است. این فرآیند میتواند بدون نیاز به مراحل دستی متعدد انجام شود و به نتایج بسیار چشمگیری بینجامد. با این حال، در صورت عدم برنامهریزی و تدوین استراتژیهای مناسب، متأسفانه ممکن است به نتایج زیانباری برای کاربران، محصول شما و جامعه بهطور کلی منجر شود.
بیایید به بررسی چند نمونه (اما نه همه) از این نتایج بالقوه مضر بپردازیم:
توهمات
توهمات اصطلاحی است که به وضعیتی اشاره میکند که در آن یک مدل زبان بزرگ (LLM) محتوایی تولید مینماید که یا بهطور کامل بیمعنی است یا بر اساس اطلاعات دیگر، واقعیت آن نادرست است.
بهعنوان مثال، فرض کنید که ما ویژگیای برای استارتاپ خود طراحی کردهایم که به دانشآموزان این امکان را میدهد که از یک مدل سوالات تاریخی مطرح کنند. یک دانشآموز چنین سوالی را مطرح میکند: تنها بازمانده تایتانیک چه فردی بود؟
مدل ممکن است پاسخی ارائه دهد که به صورت زیر باشد:

(Source: Flying bisons)
این پاسخ بسیار مطمئن و جامع به نظر میرسد، اما متأسفانه نادرست است. حتی با انجام تحقیقات حداقلی، میتوان دریافت که بیش از یک بازمانده در فاجعه تایتانیک وجود داشته است. برای دانشجویی که تازه به مطالعه این موضوع پرداخته، این پاسخ میتواند به اندازهای قانعکننده باشد که به سادگی مورد سؤال قرار نگیرد و به عنوان واقعیت پذیرفته شود. عواقب این امر میتواند منجر به بیاعتمادی نسبت به سیستم هوش مصنوعی شود و تأثیرات منفی بر شهرت استارتاپ ما داشته باشد.
با هر بار تکرار از هر مدل زبان بزرگ (LLM)، شاهد بهبودهایی در عملکرد به منظور کاهش نادرستیها بودهایم. با وجود این پیشرفتها، ما به عنوان طراحان و کاربران برنامهها باید همچنان از این محدودیتها آگاه باشیم.
محتوای مضر
در بخش قبلی در مورد مواقعی که یک مدل زبان بزرگ (LLM) پاسخهای نادرست یا بیمعنی تولید میکند، به بحث پرداختیم. یکی دیگر از خطراتی که نیاز به توجه دارد، زمانی است که یک مدل با محتوای مضر پاسخ میدهد.
محتوای مضر را میتوان به این صورت تعریف کرد:
- ارائه دستورالعملها یا تشویق به خودآسیبی یا آسیب به گروههای خاص.
- محتوای نفرتانگیز یا تحقیرآمیز.
- ارائه دستورالعمل در زمینه نحوه دستیابی به محتوای غیرقانونی یا ارتکاب اعمال غیرقانونی.
هدف ما در استارتاپ این است که اطمینان حاصل کنیم ابزارها و استراتژیهای مناسبی برای جلوگیری از مشاهده این نوع محتوا توسط دانشآموزان در اختیار داریم.
عدم انصاف (Lack of Fairness)
عدم انصاف به این معناست که "یک سیستم هوش مصنوعی بدون جانبداری و تبعیض عمل کند و با همه به طور عادلانه و برابر رفتار نماید." در دنیای هوش مصنوعی تولیدی، ما باید اطمینان حاصل کنیم که نگرشهای انحصارطلبانه گروههای حاشیهنشین توسط تولیدات مدل تقویت نگردد.
این نوع تولیدات نه تنها به تجربه مثبت کاربران آسیب میزند، بلکه موجب ایجاد مشکلات اجتماعی بیشتری میشود. به عنوان طراحان و سازندگان برنامه، هنگام توسعه راهحلهایی با بهرهگیری از هوش مصنوعی تولیدی باید همواره یک پایگاه کاربری وسیع و متنوع را در نظر داشته باشیم.
نحوه استفاده مسئولانه از هوش مصنوعی مولد
اکنون که به اهمیت استفاده مسئولانه از هوش مصنوعی مولد پی بردهایم، بیایید به چهار مرحلهای که میتوانیم برای توسعه راهحلهای هوش مصنوعی خود بهصورت مسئولانه اتخاذ کنیم، بپردازیم:
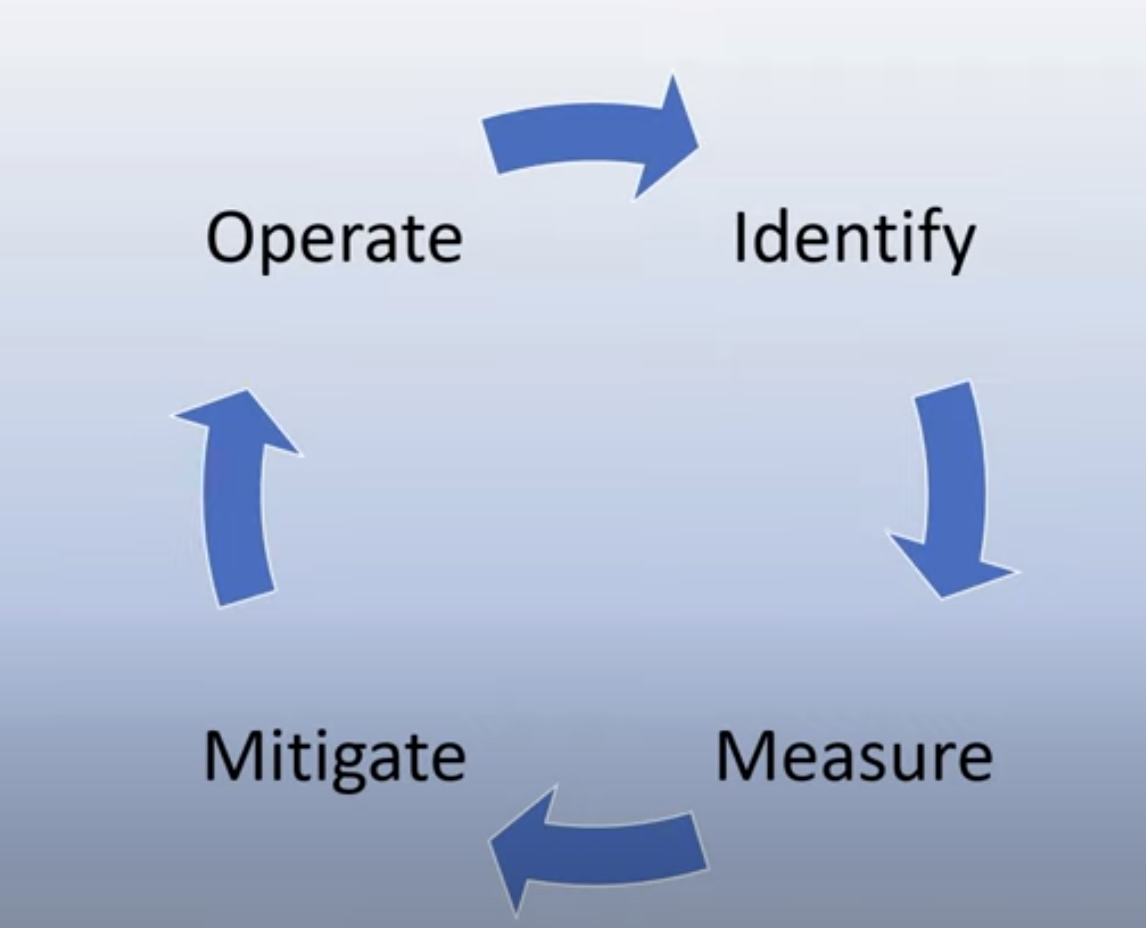
اندازهگیری آسیبهای بالقوه
در آزمایش نرمافزار، ما عملکردهای مورد انتظار یک کاربر را بر روی یک برنامه آزمایش میکنیم. به همین ترتیب، آزمایش مجموعهای متنوع از پرسشهای کاربران که احتمالاً از آنها استفاده خواهند کرد، روشی مناسب برای اندازهگیری آسیبهای بالقوه است.
از آنجا که استارتاپ ما محصولی در حوزه آموزش را توسعه میدهد، تهیه فهرستی از پرسشهای مرتبط با آموزش میتواند مفید باشد. این پرسشها میتواند شامل موضوعات خاص، حقایق تاریخی و سوالات مربوط به زندگی دانش آموزی باشد.
کاهش آسیبهای بالقوه
اکنون زمان آن فرارسیده است که روشهایی را برای جلوگیری یا محدود کردن آسیبهای بالقوهای که ممکن است به واسطه مدل و پاسخهای آن ایجاد شود، بیابیم. ما میتوانیم به این موضوع در چهار لایه مختلف بپردازیم:
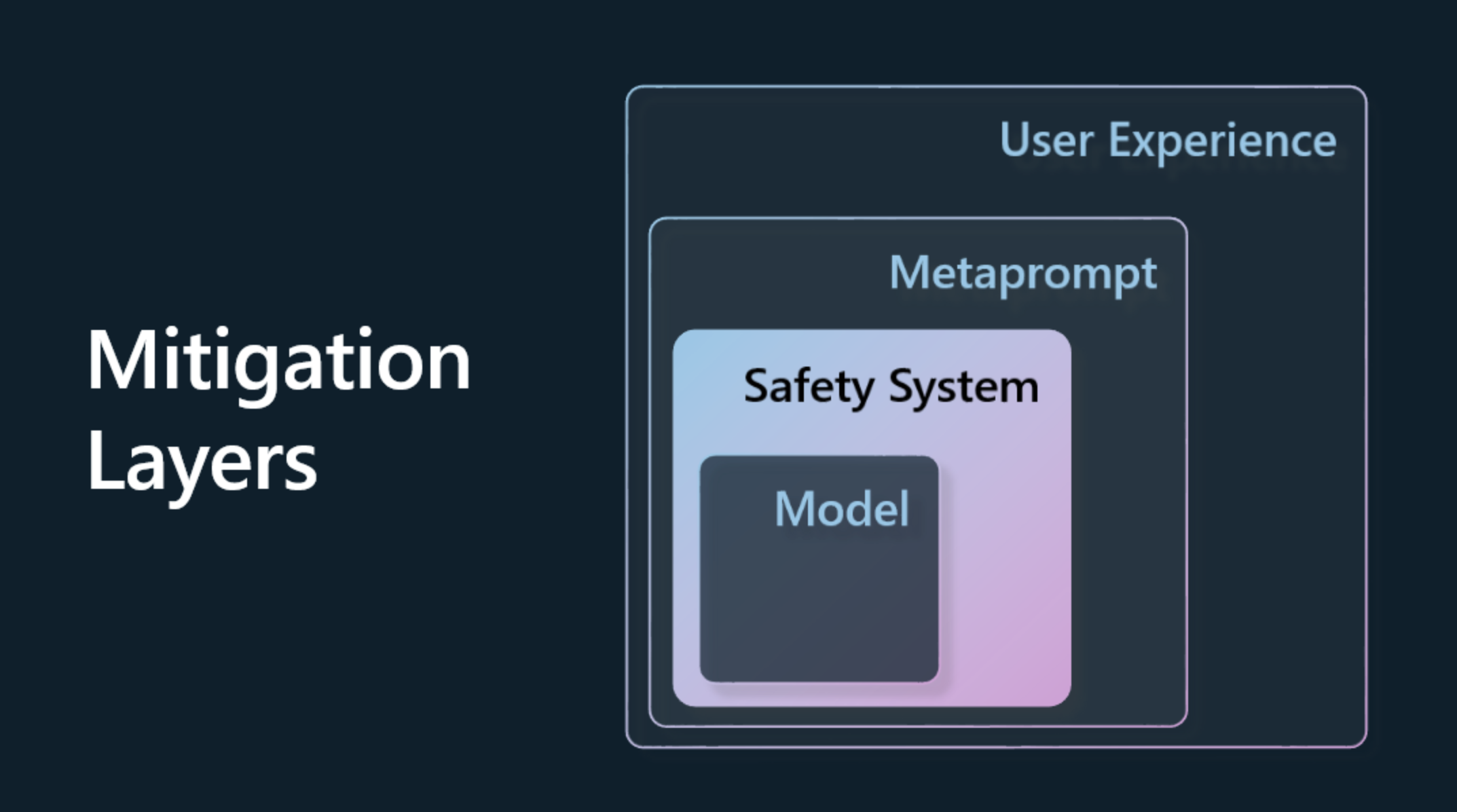
-
مدل. انتخاب مدل مناسب برای کاربرد خاص. مدلهای بزرگتر و پیچیدهتر مانند GPT-4 ممکن است هنگام بهکارگیری در موارد خاص و محدود، خطر تولید محتوای مضر را افزایش دهند. استفاده از دادههای آموزشی برای بهینهسازی مدل نیز میتواند این خطر را کاهش دهد.
-
سیستم ایمنی. سیستم ایمنی مجموعهای از ابزارها و پیکربندیها در پلتفرم ارائهدهنده مدل است که به کاهش آسیب کمک میکند. به عنوان نمونه، سیستم فیلتر محتوای خدمات Azure OpenAI وجود دارد. این سیستمها باید قابلیت شناسایی حملات شکستن (jailbreak) و فعالیتهای نامطلوب مانند درخواستهای رباتها را داشته باشند.
-
متاپرامپت. متاپرامپتها و زمینهگذاری، روشهایی هستند که میتوانند ما را در جهتدهی یا محدود کردن مدل بر اساس رفتارها و اطلاعات خاص یاری کنند. این ممکن است شامل استفاده از ورودیهای سیستمی باشد که محدودیتهای خاصی را برای مدل مشخص میکند. علاوه بر این، ارائه خروجیهایی که با دامنه یا حوزه سیستم مرتبطتر باشد، نیز مورد نظر است.
این تکنیکها همچنین میتوانند شامل تولید تقویتشده با بازیابی (RAG) باشد که در آن مدل تنها اطلاعات را از مجموعهای از منابع معتبر استخراج میکند. در درسهای بعدی این دوره، درس دیگری تحت عنوان ساخت برنامههای جستجو ارائه شده است.
- تجربه کاربر. لایه نهایی، جایی است که کاربر بهطور مستقیم از طریق رابط کاربری برنامه ما با مدل تعامل میکند. به این ترتیب، میتوانیم رابط کاربری و تجربه کاربری (UI/UX) را بهگونهای طراحی کنیم که نوع ورودیهایی را که کاربران میتوانند به مدل ارسال کنند و همچنین متن یا تصاویری را که به کاربر نمایش داده میشود، محدود نماییم. هنگام پیادهسازی برنامه هوش مصنوعی، همچنین باید در مورد قابلیتها و محدودیتهای برنامه هوش مصنوعی مولد خود، شفافیت لازم را داشته باشیم.
ما درس کاملی به طراحی تجربه کاربری برای برنامههای هوش مصنوعی اختصاص دادهایم.
- ارزیابی مدل. کار با مدلهای زبانی بزرگ (LLM) میتواند چالشبرانگیز باشد، زیرا ما همیشه کنترل کاملی بر دادههایی که مدل بر اساس آنها آموزش دیده است، نداریم. با این حال، باید همواره عملکرد و خروجیهای مدل را ارزیابی کنیم. اندازهگیری دقت، شباهت، اعتبار و ارتباط خروجی، همچنان مهم و ضروری است. این امر به افزایش شفافیت و اعتماد ذینفعان و کاربران کمک خواهد کرد.
راهاندازی راهحلهای مسئولانه هوش مصنوعی مولد
ایجاد یک رویه عملیاتی در زمینهی کاربردهای هوش مصنوعی، مرحلهی نهایی به شمار میآید. این امر شامل همکاری با سایر بخشهای استارتاپ، نظیر بخش حقوقی و امنیتی، بهمنظور اطمینان از انطباق با تمامی سیاستهای قانونی است. پیش از راهاندازی، نیاز داریم برای تحویل، مدیریت حوادث و بازگشت به وضعیت قبلی برنامهریزی کنیم تا از بروز هرگونه آسیب به کاربرانمان جلوگیری کنیم.