علم داده چیست و چه کاری با داده میتوان انجام داد؟
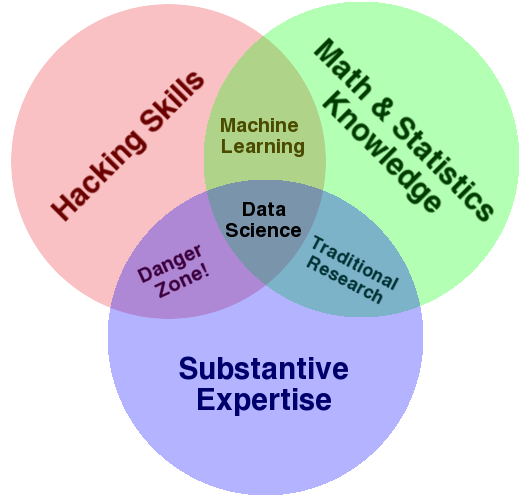
تعریف علم داده
داده چیست ؟
در زندگی روزمره ما، ما همیشه توسط داده ها احاطه شده ایم. متنی که اکنون می خوانید داده است. لیست شماره تلفن دوستان شما در گوشی هوشمندتان داده است، همچنین ساعت فعلی نمایش داده شده بر روی ساعتتان داده است. به عنوان انسان ها، ما به طور طبیعی با داده ها کار می کنیم، مانند شمردن پولی که داریم یا نوشتن نامه به دوستانمان.
با این حال، داده ها با ایجاد کامپیوترها بسیار مهم تر شدند. نقش اصلی کامپیوترها انجام محاسبات است، اما آنها به داده ها برای کار کردن نیاز دارند. بنابراین، ما باید بفهمیم که کامپیوترها چگونه داده ها را ذخیره و پردازش می کنند.
با ظهور اینترنت، نقش کامپیوترها به عنوان دستگاه های پردازش داده افزایش یافت. اگر درباره آن فکر کنید، اکنون ما از کامپیوترها بیشتر برای پردازش داده ها و ارتباطات استفاده می کنیم، تا محاسبات واقعی. هنگامی که ایمیل به دوستمان می نویسیم یا به دنبال اطلاعات خاصی در اینترنت می گردیم - ما در واقع داده ها را ایجاد، ذخیره، انتقال و دستکاری می کنیم.
آیا می توانید آخرین باری را که از کامپیوتر برای محاسبه چیزی استفاده کرده اید به یاد آورید؟
علم داده چیست ؟
در ویکی پدیا، علم داده به عنوان یک حوزه علمی تعریف می شود که از روش های علمی برای استخراج دانش و بینش از داده های ساختار یافته و غیر ساختار یافته استفاده می کند و دانش و بینش های عملی از داده را در طیف وسیعی از حوزه های کاربرد اعمال می کند.
این تعریف جنبه های مهم زیر از علم داده را برجسته می کند:
- هدف اصلی علم داده استخراج دانش از داده است، به عبارت دیگر - درک داده، پیدا کردن برخی روابط پنهان و ساخت مدل.
- علم داده از روش های علمی مانند احتمال و آمار استفاده می کند. در واقع، هنگامی که اصطلاح علم داده برای اولین بار معرفی شد، برخی از افراد استدلال کردند که علم داده فقط یک نام جدید برای آمار است. اما اکنون روشن شده است که این حوزه بسیار گسترده تر است.
- دانش به دست آمده باید برای تولید بینش های عملی اعمال شود، یعنی بینش های عملی که می توانید در وضعیت های تجاری واقعی اعمال کنید.
- ما باید بتوانیم بر روی داده های ساختار یافته و غیر ساختار یافته کار کنیم. ما بعدا در طول دوره به بحث درباره انواع مختلف داده باز خواهیم گشت.
- حوزه کاربرد یک مفهوم مهم است و دانشمندان داده اغلب به حداقل درجه ای از تخصص در حوزه مسئله، برای مثال، مالی، پزشکی، بازاریابی و غیره نیاز دارند.
جنبه دیگری از علم داده این است که چگونه داده ها را می توان جمع آوری، ذخیره و با استفاده از کامپیوترها پردازش کرد. در حالی که آمار مبانی ریاضی را به ما می دهد، علم داده مفاهیم ریاضی را به کار می گیرد تا بینش های واقعی از داده ها استخراج کند.
یکی از راه ها (نسبت داده شده به جیم گری) برای نگاه به علم داده این است که آن را به عنوان یک پارادایم علمی جدا در نظر بگیریم:
- تجربی، که در آن ما بیشتر به مشاهدات و نتایج آزمایش ها اعتماد می کنیم.
- نظری، که مفاهیم جدید از دانش علمی موجود ظاهر می شوند.
- محاسباتی، که ما اصول جدید را بر اساس برخی آزمایش های محاسباتی کشف می کنیم.
- داده محور، که بر اساس کشف روابط و الگوها در داده ها است.
سایر زمینه های مرتبط
از آنجا که داده همه جا حاضر است، علم داده خود نیز یک حوزه گسترده است که بسیاری از رشته های دیگر را لمس می کند.
پایگاه داده ها (Databases)
یک موضوع مهم این است که چگونه داده ها را ذخیره کنیم، یعنی چگونه آن را در ساختاری سازمان دهیم که اجازه پردازش سریع تر را بدهد. انواع مختلف پایگاه داده ها وجود دارند که داده های ساخت یافته و غیر ساخت یافته را ذخیره می کنند.
داده بزرگ (Big Data)
اغلب ما نیاز داریم که مقادیر بسیار بزرگی از داده ها را با ساختار نسبتا ساده ذخیره و پردازش کنیم. روش های خاص و ابزارهایی برای ذخیره آن داده ها در یک خوشه کامپیوتری و پردازش کارآمد آنها وجود دارد.
یادگیری ماشینی (Machine Learning)
یکی از راه های درک داده این است که مدل هایی را بسازیم که بتوانند نتیجه مورد نظر را پیش بینی کنند. توسعه مدل ها از داده ها را یادگیری ماشینی می نامند.
هوش مصنوعی (Artificial Intelligence)
یک حوزه از یادگیری ماشینی به نام هوش مصنوعی (AI) نیز به داده ها وابسته است و شامل ساخت مدل های پیچیده ای است که فرآیندهای تفکر انسانی را تقلید می کنند. روش های AI اغلب اجازه می دهند که داده های غیر ساخت یافته (مثل زبان طبیعی) را به بینش های ساخت یافته تبدیل کنیم.
مصور سازی (Visualization)
مقدار زیادی از دادهها برای یک انسان غیرقابل درک است، اما هنگامی که تجسمهای مفید از آن دادهها را ایجاد کنیم، میتوانیم به درک بیشتری از آن دادهها برسیم و برخی از نتیجهگیریها را انجام دهیم. بنابراین، مهم است که با روشهای گوناگون تجسم اطلاعات آشنا باشیم.
انواع داده
همانطور که قبلا اشاره کردیم، داده همه جا حاضر است. ما فقط به روش درست به دست آوردن آن نیاز داریم. مفید است که میان دادههای ساختیافته و غیرساختیافته تمایز قائل شویم. اولی معمولا در فرم ساختیافتهای نمایان میشود، اغلب به صورت جدول یا تعداد جدولها، در حالی که دومی فقط مجموعهای از فایلها است. گاهی اوقات ما همچنین میتوانیم درباره دادههای نیمهساختیافته صحبت کنیم، که دارای برخی نوع ساختار هستند که ممکن است به شدت متفاوت باشد.
| ساختار یافته | نیمه ساختار یافته | بی ساختار |
|---|---|---|
| فهرست افراد با شمارههای تلفن آنها | صفحات ویکیپدیا با لینکها | متن دائرةالمعارف بریتانیکا |
| دما در همه اتاقهای یک ساختمان در هر دقیقه برای ۲۰ سال گذشته | صفحات اینترنتی | اسناد شرکتی |
| دادههای سنی و جنسیت همه افراد وارد شده به ساختمان | مجموعه مقالههای علمی در فرمت JSON با نویسندگان، تاریخ انتشار و چکیده | فید ویدیویی خام از دوربین نظارتی |
از کجا داده بگیریم ؟
اگرچه لیست کردن همه منابع داده امکانپذیر نیست، اما بیایید برخی از منابع معمولی داده را ذکر کنیم:
- ساختار یافته
- دادههای اینترنت اشیا (IoT) شامل دادههای مختلف سنسورها، مانند سنسورهای دما یا فشار، مقدار زیادی داده مفید فراهم میکنند. برای مثال، اگر یک ساختمان اداری با سنسورهای IoT تجهیز شده باشد، میتوانیم به صورت خودکار گرمایش و روشنایی را کنترل کنیم تا هزینهها را به حداقل برسانیم.
- پرسشنامههایی که از کاربران میخواهیم پس از خرید یا پس از بازدید از یک سایت، تکمیل کنند.
- تجزیه رفتار میتواند، برای مثال، به ما کمک کند تا بفهمیم که یک کاربر تا چه حد در یک سایت پیش میرود و دلیل معمول ترک سایت چیست.
- بی ساختار
- متون میتوانند منبع غنی از بینشها باشند، مانند امتیاز کلی احساسات یا استخراج کلمات کلیدی.
- تصاویر یا ویدیو. یک ویدیو از دوربین نظارتی میتواند برای برآورد ترافیک در جاده و اطلاعرسانی به مردم درباره ترافیک احتمالی استفاده شود.
- لاگهای سرور وب میتوانند برای فهمیدن اینکه کدام صفحات سایت ما بیشتر بازدید میشوند و برای چه مدت، استفاده شوند.
- نیمه ساختار یافته
- گرافهای شبکه اجتماعی میتوانند منابع بزرگی از داده درباره شخصیتهای کاربر و کارایی بالقوه در پخش اطلاعات باشند.
با دانستن منابع مختلف داده، میتوانید سعی کنید درباره سناریوهای مختلفی فکر کنید که تکنیکهای علم داده میتوانند برای فهم بهتر وضعیت و بهبود فرآیندهای تجاری استفاده شوند.
چه کاری با داده میتوان انجام داد؟
در علم داده، ما بر روی گامهای زیر از مسیر داده تمرکز میکنیم:
جمعآوری داده. اولین گام جمعآوری داده است. در حالی که در بسیاری از موارد میتواند یک فرآیند مستقیم باشد، مانند دادههایی که از یک برنامه وب به دیتابیس میآیند، گاهی اوقات به تکنیکهای ویژه نیاز داریم. برای مثال، دادههای حاصل از سنسورهای اینترنت اشیا (IoT) میتواند بسیار زیاد باشد و استفاده از بافرینگ دادهها مانند هاب اینترنت اشیا برای جمعآوری همه دادهها قبل از پردازش بیشتر یک شیوه خوب است.
ذخیرهسازی داده. ذخیرهسازی داده میتواند چالشبرانگیز باشد، به ویژه اگر درباره دادههای بزرگ صحبت کنیم. هنگام تصمیمگیری درباره چگونگی ذخیرهسازی داده، منطقی است که انتظار داشته باشیم چگونه دادهها را در آینده پرس و جو کنیم. چندین راه برای ذخیرهسازی دادهها وجود دارد:
- یک دیتابیس رابطهای مجموعهای از جداول را ذخیره میکند و از زبان ویژهای به نام SQL برای پرس و جو از آنها استفاده میکند. معمولاً جداول به گروههای مختلفی به نام طرحها سازماندهی میشوند. در بسیاری از موارد، ما نیاز داریم دادهها را از فرم اصلی به فرم مناسب برای طرح تبدیل کنیم.
- یک دیتابیس NoSQL، مانند MongoDB، طرحها را بر روی دادهها اعمال نمیکند و اجازه میدهد دادههای پیچیدهتری، مانند سندهای JSON سلسلهمراتب یا گرافها، ذخیره شوند. با این حال، دیتابیسهای NoSQL قابلیت پرس و جو غنی SQL را ندارند و نمیتوانند یکپارچگی ارجاعی را اعمال کنند، یعنی قواعدی که ساختار دادهها در جداول و روابط بین جداول را اداره میکنند.
- انبار داده دریا برای مجموعههای بزرگ داده در فرم خام و بدون ساختار استفاده میشود. دریاچههای داده معمولاً با دادههای بزرگ استفاده میشوند، جایی که همه دادهها نمیتوانند در یک ماشین قرار بگیرند و باید توسط خوشهای از سرورها ذخیره و پردازش شوند. پارکت فرمت دادهای است که معمولاً همراه با دادههای بزرگ استفاده میشود.
پردازش داده. این بخش هیجانانگیزترین قسمت از سفر داده است که شامل تبدیل دادهها از فرم اصلی به فرم قابل استفاده برای تجسم/آموزش مدل است. هنگام کار با دادههای بدون ساختار مانند متن یا تصاویر، ممکن است به برخی تکنیکهای هوش مصنوعی برای استخراج ویژگیها از دادهها نیاز داشته باشیم، بنابراین آن را به فرم ساختاری تبدیل میکنیم.
مصور سازی/ بینش انسانی. اغلب، برای درک دادهها، نیاز داریم آنها را به تصویر بکشیم. با داشتن تکنیکهای تجسم مختلف در جعبه ابزارمان، میتوانیم نمای درست را برای کسب بینش پیدا کنیم. اغلب، یک دانشمند داده باید «با دادهها بازی کند»، آنها را چندین بار تجسم کند و به دنبال روابطی بگردد. همچنین، ممکن است از تکنیکهای آماری برای آزمایش فرضیهها یا اثبات همبستگی بین قطعات مختلف داده استفاده کنیم.
آموزش مدل پیشبینی. چون هدف نهایی علم داده این است که بتوانیم بر اساس دادهها تصمیم بگیریم، ممکن است بخواهیم از تکنیکهای یادگیری ماشین برای ساخت مدل پیشبینی استفاده کنیم. سپس میتوانیم از آن برای پیشبینی با استفاده از مجموعه دادههای جدید با ساختار مشابه استفاده کنیم.
البته بسته به داده واقعی، برخی از گامها ممکن است حذف شوند (برای مثال، وقتی که دادهها را در دیتابیس داریم یا وقتی که به آموزش مدل نیاز نداریم)، یا برخی از گامها ممکن است چندین بار تکرار شوند (مانند پردازش داده).
دیجیتالی شدن و تحول دیجیتال
در دهه گذشته، بسیاری از کسب و کارها اهمیت دادهها را در تصمیمگیریهای تجاری درک کردند. برای اعمال اصول علم دادهها در اداره کسب و کار، ابتدا باید برخی دادهها را جمعآوری کرد، یعنی فرآیندهای تجاری را به فرم دیجیتال ترجمه کرد. این فرایند دیجیتالی کردن نامیده میشود. اعمال تکنیکهای علم دادهها به این دادهها برای هدایت تصمیمگیریها میتواند به افزایش قابل توجهی در بهرهوری (یا حتی تغییر جهت کسب و کار) منجر شود، که تبدیل دیجیتال نامیده میشود.
بیایید به یک مثال توجه کنیم. فرض کنید ما یک دوره علم دادهها (مانند این دوره) داریم که به صورت آنلاین به دانشجویان ارائه میکنیم و میخواهیم از علم دادهها برای بهبود آن استفاده کنیم. چگونه میتوانیم این کار را انجام دهیم؟
میتوانیم با پرسیدن "چه چیزی میتواند دیجیتالی شود؟" شروع کنیم. سادهترین راه این است که زمان لازم برای تکمیل هر ماژول توسط هر دانشجو را اندازهگیری کنیم و دانش به دست آمده را با دادن یک آزمون چند گزینهای در پایان هر ماژول اندازهگیری کنیم. با میانگینگیری زمان تکمیل در میان همه دانشجویان، میتوانیم بفهمیم که کدام ماژولها برای دانشجویان بیشترین مشکلات را ایجاد میکنند و بر روی سادهسازی آنها کار کنیم.
شما ممکن است استدلال کنید که این روش ایدهآل نیست، زیرا ماژولها میتوانند طولهای مختلفی داشته باشند. احتمالاً عادلانهتر است که زمان را به طول ماژول (تعداد کاراکترها) تقسیم کنیم و آن ارزشها را مقایسه کنیم.
وقتی ما شروع به تجزیه نتایج آزمونهای چند گزینهای میکنیم، میتوانیم سعی کنیم تعیین کنیم که کدام مفاهیم را دانشآموزان درک نمیکنند و از آن اطلاعات برای بهبود محتوا استفاده کنیم. برای انجام این کار، ما نیاز داریم آزمونها را به گونهای طراحی کنیم که هر سوال به یک مفهوم یا بخش خاصی از دانش مرتبط باشد.
اگر بخواهیم پیچیدگی بیشتری داشته باشیم، میتوانیم زمان صرف شده برای هر ماژول را در برابر دسته سنی دانشآموزان ترسیم کنیم. ممکن است کشف کنیم که برای برخی از دستههای سنی، زمان زیادی برای تکمیل ماژول صرف میشود یا اینکه دانشآموزان قبل از تکمیل آن رها میکنند. این میتواند به ما کمک کند تا توصیههای سنی برای ماژول ارائه دهیم و نارضایتی مردم از انتظارات نادرست را به حداقل برسانیم.
تشکر
تشکر از مایکروسافت برای ایجاد دوره بازمتن علم داده برای مبتدیان. این دوره الهامبخش اکثریت محتوای این مطلب است.