شبکههای پیشآموزشدیده و یادگیری انتقالی
آموزش شبکههای عصبی عمیق پیچشی (CNN) ممکن است زمانبر باشد و به دادههای وسیع نیاز دارد. با این حال، بخشی از زمان به یادگیری بهترین فیلترهای سطح پایین اختصاص مییابد تا شبکه بتواند الگوها را از تصاویر استخراج کند. پرسش طبیعی این است که آیا میتوانیم از یک شبکه عصبی که بر روی یک مجموعه داده آموزش دیده است استفاده کنیم و آن را برای طبقهبندی تصاویر مختلف تطبیق دهیم بدون اینکه به یک فرآیند آموزش کامل نیاز داشته باشیم؟
این رویکرد به نام یادگیری انتقالی شناخته میشود، زیرا ما برخی از دانشها را از یک مدل شبکه عصبی به مدل دیگری منتقل میکنیم. در یادگیری انتقالی، معمولاً از یک مدل پیشآموزشدیده شروع میکنیم که بر روی یک مجموعه داده بزرگ از تصاویر، نظیر ImageNet آموزش دیده است. این مدلها میتوانند در استخراج ویژگیهای متنوع از تصاویر عمومی عملکرد خوبی داشته باشند و در بسیاری از موارد، تنها ایجاد یک طبقهبند بر اساس ویژگیهای استخراجشده میتواند به نتایج رضایتبخشی منجر شود.
✅ یادگیری انتقالی اصطلاحی است که در زمینههای مختلف علمی، از جمله آموزش، نیز به کار میرود. این اصطلاح به فرآیند انتقال دانش از یک حوزه به حوزهای دیگر اشاره دارد.
مدلهای پیشآموزشدیده به عنوان استخراجکننده ویژگی
شبکههای پیچشی که در بخش قبلی مطرح شدند شامل تعدادی لایه هستند که هر یک به استخراج ویژگیهایی از تصویر میپردازند، از ترکیبهای پیکسلهای سطح پایین (مانند خطوط افقی/عمودی یا نوارها) آغاز میشود و به ترکیبهای سطح بالاتر از ویژگیها میرسد که به چیزهایی مانند چشم مربوط میشود. اگر یک شبکه CNN را بر روی یک مجموعه داده بزرگ و متنوع از تصاویر عمومی آموزش دهیم، باید یاد بگیرد که آن ویژگیهای مشترک را استخراج کند.
هر دو Keras و PyTorch شامل توابعی هستند که به آسانی میتوانند وزنهای پیشآموزشدیده شبکههای عصبی را برای چندین معماری رایج بارگذاری کنند، که بیشتر آنها بر روی تصاویر ImageNet آموزش دیدهاند. معمولاً از مدلهای زیر، که در صفحه معماریهای CNN درس قبلی توضیح داده شدهاند، استفاده میشود. بهویژه، ممکن است بخواهید از یکی از موارد زیر بهره بگیرید:
- VGG-16/VGG-19 که مدلهای نسبتاً سادهای هستند و هنوز هم دقت مناسب را ارائه میدهند. غالباً استفاده از VGG بهعنوان اولین تلاش انتخاب خوبی است تا عملکرد یادگیری انتقالی را بررسی کنیم.
- ResNet، خانوادهای از مدلها که توسط Microsoft Research در سال 2015 معرفی شده است. این مدلها لایههای بیشتری دارند و بنابراین به منابع بیشتری نیاز دارند.
- MobileNet، خانوادهای از مدلها با اندازه کاهشیافته که برای دستگاههای موبایل بهینهسازی شدهاند. از آنها در صورتی که منابع محدود دارید و میتوانید مقداری از دقت را فدای آن کنید، استفاده کنید.
در اینجا نمونهای از ویژگیهای استخراجشده از تصویری از یک گربه توسط شبکه VGG-16 آورده شده است:

مجموعه داده گربهها و سگها
در این مثال، ما از مجموعه دادهای گربهها و سگها استفاده خواهیم کرد که بهطور قابل توجهی به یک سناریوی واقعی طبقهبندی تصویر نزدیک است.
✍️ تمرین: یادگیری انتقالی
بیایید یادگیری انتقالی را در عمل در دفاتر کار مربوطه مشاهده کنیم:
تجسم گربه ایدهآل
شبکه عصبی پیشآموزشدیده الگوهای متنوعی را در ذهن خود دارد، از جمله مفاهیم گربه ایدهآل (همچنین سگ ایدهآل، گورخر ایدهآل و غیره). جالب است که به نوعی این تصویر را تجسم کنیم. با این حال، این کار ساده نیست زیرا الگوها در سرتاسر وزنهای شبکه پخش شده و در یک ساختار سلسلهمراتبی سازماندهی شدهاند.
یکی از رویکردهایی که میتوانیم اتخاذ کنیم این است که با یک تصویر تصادفی آغاز کنیم و سپس سعی کنیم از تکنیک بهینهسازی نزولی گرادیانت بهرهبرداری کنیم تا آن تصویر بهگونهای تنظیم شود که شبکه به فکر بیفتد که این یک گربه است.
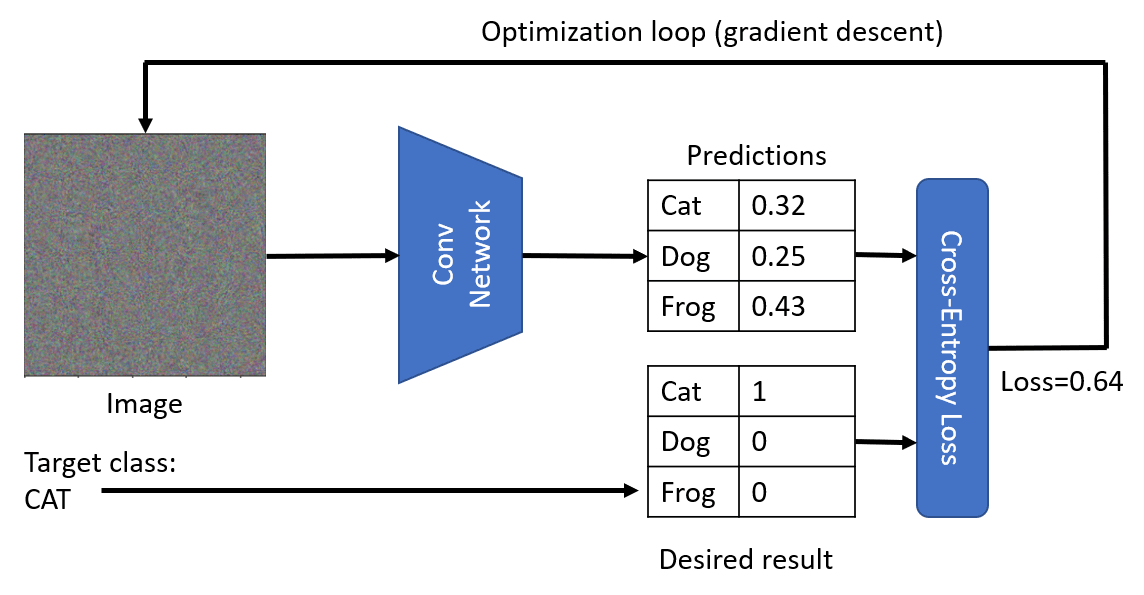
با این حال، اگر این کار را انجام دهیم، نتیجهای بسیار مشابه با نویز تصادفی خواهیم گرفت. این ناشی از آن است که راههای متعددی برای وادار کردن یک شبکه به درک تصویر ورودی بهعنوان یک گربه وجود دارد که شامل برخی روشهایی است که از نظر بصری بیمعناست. اگرچه این تصاویر الگوهای زیادی دارند که مختص گربه هستند، اما هیچ چیز آنها را از نظر بصری متمایز نمیکند.
به منظور بهبود نتیجه، میتوانیم یک اصطلاح دیگر به تابع هزینه اضافه کنیم که به آن هزینه تغییر میگویند. این معیار نشاندهنده شباهت همسایههای پیکسلهای تصویر است. کاهش هزینه تغییر، تصویر را هموارتر میکند و از نویز خلاص میشود - و بدینترتیب الگوهای بصری جذابتری را نمایان میکند. در اینجا مثالی از چنین تصاویر "ایدهآل" آورده شده است که به احتمال زیاد بهعنوان گربه و گورخر طبقهبندی میشوند:
 |  |
|---|---|
| گربه ایدهآل | گورخر ایدهآل |
رویکرد مشابهی میتواند برای انجام آنچه که به آن حملات خصمانه میگویند، بر روی یک شبکه عصبی مورد استفاده قرار گیرد. فرض کنید قصد داریم یک شبکه عصبی را فریب دهیم تا یک سگ را بهعنوان گربه بازنمایی کند. اگر تصویری از یک سگ داشته باشیم که توسط شبکه بهعنوان سگ شناسایی شده است، میتوانیم آن را اندکی تنظیم کنیم اما با استفاده از بهینهسازی نزولی گرادیانت، تا زمانی که شبکه آن را بهعنوان گربه طبقهبندی کند:
 |  |
|---|---|
| تصویر اصلی یک سگ | تصویر یک سگ که بهعنوان گربه طبقهبندی شده است |
برای بازسازی نتایج بالا میتوان به کد موجود در دفتر زیر مراجعه کرد:
نتیجهگیری
با استفاده از یادگیری انتقالی، میتوانید بهسرعت یک طبقهبند برای کار طبقهبندی اشیاء سفارشی ایجاد کنید و دقت بالایی به دست آورید. میتوان دید که کارهای پیچیدهتری که اکنون حل میکنیم به قدرت محاسباتی بالاتر نیاز دارند و نمیتوانند به سادگی بر روی CPU حل شوند. در واحد بعدی سعی خواهیم کرد از یک پیادهسازی سبکتر برای آموزش همان مدل با استفاده از منابع محاسباتی پایینتر استفاده کنیم که نتیجهاش تنها کاهش دقت خواهد بود.
🚀 چالش
در نوتبوک های بالا، یادداشتهایی در پایان وجود دارد که نشان میدهد یادگیری انتقالی بهترین عملکرد را با دادههای آموزشی نسبتاً مشابه دارد (شاید نوع جدیدی از حیوان). چند آزمایش با انواع کاملاً جدیدی از تصاویر انجام دهید تا ببینید مدلهای یادگیری انتقالی شما چهقدر خوب یا بد عمل میکنند.
مرور و خودآموزی
از طریق تکنیکهای آموزشی مطالعه کنید تا دانش خود را درباره برخی دیگر از روشهای آموزش مدلهای خود عمیقتر کنید.
وظیفه
در این آزمایش، ما از مجموعه داده واقعی Oxford-IIIT با 35 نژاد گربه و سگ استفاده خواهیم کرد و یک طبقهبند یادگیری انتقالی خواهیم ساخت.